최근에는 어떤 어플리케이션에서든 추천시스템을 사용하는 듯 하다. 패션, 커머스는 물론이거니와 증권, 금융사, 교육 쪽에서도 추천시스템은 화두가 되고 있다.
추천 시스템 알고리즘이 점점 뜨고 있는만큼, 추천시스템이나 검색어시스템 안에서 모델의 정확성을 판단하는 것도 중요하다. 특히나, 랭킹 기반으로 추천할 때 평가할 수 있는 지표에 대해서 오늘은 이야기해보려고 한다.
1. 예측값의 정답 여부 정의
지표에 대해 이야기 하기에 앞서, 정답 여부에 대한 정의가 어떤 것이 있는지 한번 생각해보고자 한다. 앞으로 설명할 지표에서는 정답여부를 관련있다(Relevant)라고 말하고 있다.
커머스 분야의 경우 관련있다의 정의는 무조건 구매 여부를 가지고 판단할 수 는 없다. 사용자마다 정의하기 나름인데, 보통 클릭여부, 구매여부, 장바구니 담기 여부 등으로 정의하곤 한다.
검색어 추천 모델에서는 검색어 클릭 여부가 관련있다라고 판단할 수 있을 것 같다.
2. MRR(Mean Reciprocal Rank)
2.1 정의
MRR(Mean Reciprocal Rank)는 우선순위를 고려한 평가기준 중 가장 간단한 모델이라고 할 수 있다. 계산 방법은 아래와 같다.
1. 각 사용자마다 제공한 추천 컨텐츠 중에서 관련있는 컨텐츠의 가장 높은 위치를 역수로 계산한다(1/k)
2. 사용자마다 계산된 점수를 모아 평균을 계산한다.
아래 그림을 보면 이해하기가 조금 더 쉽다.

2.2 장점
MRR의 가장 큰 장점은 간단하고 쉽다는 점이며, 상위의 관련된 컨텐츠에만 집중하기 때문에, 사용자와 관련있는 컨텐츠가 최상위에 있는가를 평가하기 위해서 용이한 지표라고 볼 수 있다. 또한, 새로운 컨텐츠가 아닌 이미 사용자가 알고 있는 컨텐츠 중 가장 선호할만한 컨텐츠를 보여주고자 할 때 좋은 평가 기준이 된다고 한다.
2.3 단점
MRR의 단점은 가장 상위의 컨텐츠에만 집중하기 때문에 하위 추천한 컨텐츠에 대해서는 평가하지 않아 고려되지 않는다는 단점이 있다.
또한 추천하는 컨텐츠의 개수가 몇개이던 상관없이 최상위의 컨텐츠에 대해서만 평가하기 때문에 추천하는 개수에 대해서는 평가하기 어렵다는 단점이 있다.
3. MAP(Mean Average Precision)
MRR의 단점을 해결하기 위해 생각할 만한 지표가 MAP이다. 사용자 별 상위 N개까지의 정밀도(Precision@N)를 평균내는 것이다. 단순한 정밀도는 랭킹에 대한 점수를 매길 수 없으므로, MAP를 이용하여 관련있는 컨텐츠의 위치에 따라 점수에 차등을 준다. 계산 방법은 아래와 같다.
1. 각 사용자마다 관련된 컨텐츠를 구하여 각 관련 컨텐츠의 목록에 대한 정밀도를 계산한다.( 아래 그림 참조)
2. 계산된 정밀도 값들에 대하여 사용자별로 평균을 내고, 그 결과를 모두 모아 평균을 계산한다.

위와 같은 예시는 사용자 2명에게 5개의 컨텐츠를 추천했을 때 평가하는 방법에 대해서 계산한 예시다.
3.1 장점
MAP의 장점은 단순한 성능을 평가하는 것이 아니라 우선순위를 고려한 성능을 평가할 수 있다는 것이 장점이 된다.
또한 상위에 있는 오류(관련이 없는 컨텐츠)에 대해서는 가중치를 더 주고, 하위에 있는 오류에 대해서는 가중치를 적게 주어 관련 컨텐츠가 상위에 오를 수 있도록 도와준다.
3.2 단점
MAP의 단점 중 하나는, 관련 여부가 명확하지 않은 경우, 계산이 어렵다는 단점이 있다.(1~5점 평점같은 경우) 그래서 일정 기준을 주고 1, 0을 나타낼 수 있도록 이분법적인 답에 대해서만 해당 지표를 사용할 수 있다는게 하나의 단점이 될 수 있다.
4. nDCG(Normalized Discounted Cumulative Gain)
nDCG는 MAP를 이용하여 얻고자 하는 목표와 크게 다르지 않지만, MAP에서의 이분법적인 구분 지표에 대해서만 사용할 수 있는 지표를 보완한다는 점에서 가장 유용하다고 볼 수 있다. 계산 방법은 아래와 같다.
1. 모든 추천 컨텐츠들의 관련도를 합하여 CG(cumulative gain)을 구한다.
2. CG에서 추천 컨텐츠들의 관련도를 합하였다면, DCG는 각 추천 컨텐츠의 관련도를 log함수로 나누어 값을 구한다. log함수 특성상 위치 값이 클수록(하위에 있을 수록) DCG의 값을 더 작아지게 함으로써 상위 컨텐츠의 값을 점수에 더 반영할 수 있게 한다.
3. DCG 값에 관련도를 더 강조하고 싶다면, 2^관련도 - 1과 같이 관련도의 영향을 증가시킬 수 있다.
4. 사용자마다 제공되는 추천 컨텐츠의 DCG와는 별개로 IDCG(이상적인 DCG)를 미리 계산해놓는다.
5. 각 사용자의 DCG를 IDCG로 나누어서 사용자별 NDCG를 구한다.
6. 사용자별 NDCG의 평균을 구하여 해당 IR의 NDCG를 구한다.

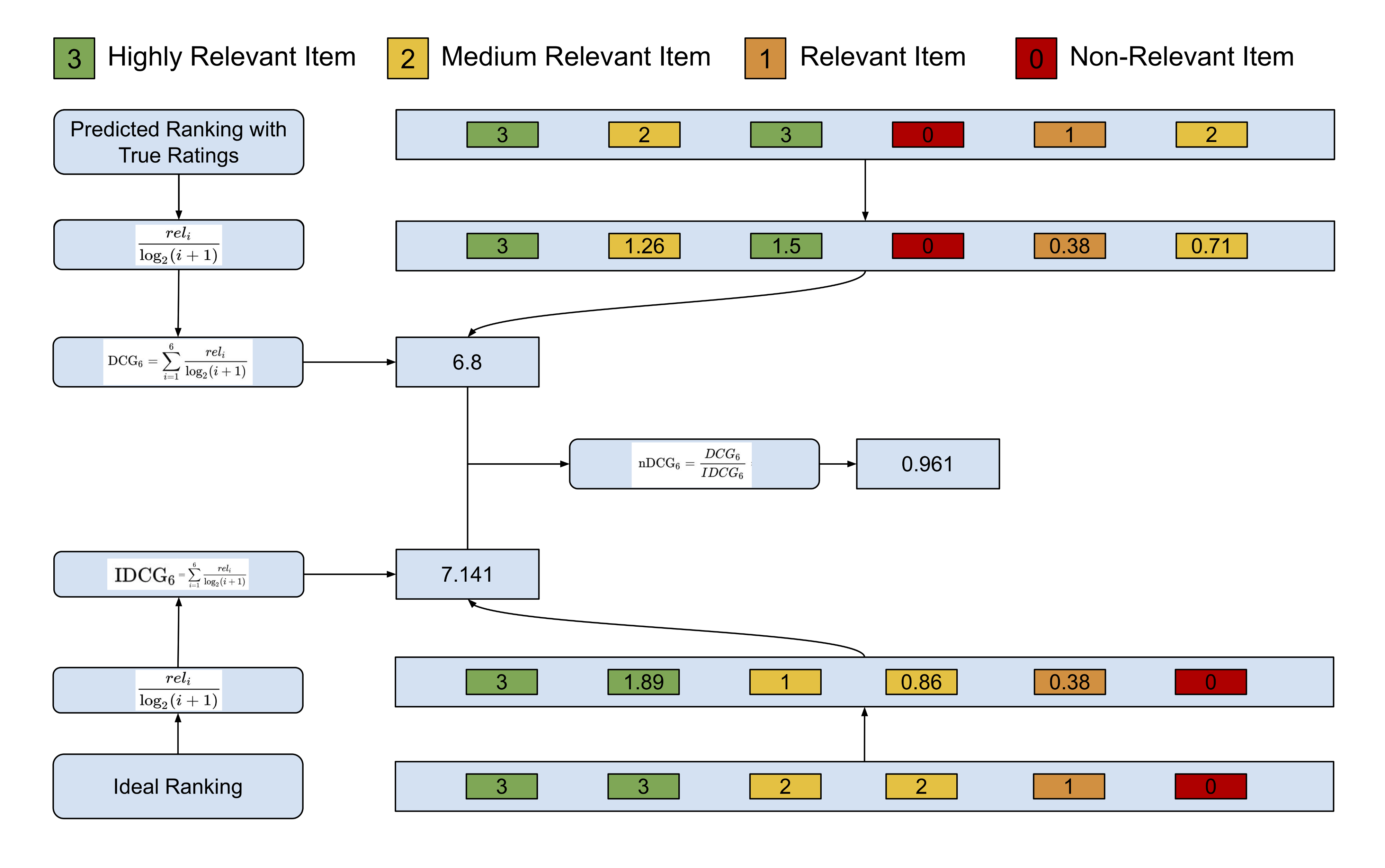
4.1 장점
nDCG는 기존 방법과는 다르게 관련도를 범주화해서 평가가 가능하다. 이분법적인 관련도에도 뛰어난 성능을 보인다고 한다. 또한 log함수를 이용하여 하위 컨텐츠에 대한 영향을 줄임으로 좋은 성능을 보인다.
4.2 단점
사용자의 관련 컨텐츠가 없다면(사용자가 평점을 입력하지 않거나 평가하지 않는다면) 임의의 값을 설정해주어야 한다. 즉, 예외처리가 필요하다는 말이다. 이 부분은 때로으는 어떤 경우에서는 문제가 될 수도 있다.
5. 마무리
이런 시스템, 알고리즘 분석을 하는 사람들은 알겠지만, 뭐든 한가지 지표만 사용하는 것은 편향도 있고 문제가 될 수 있기에, 다양한 지표를 사용하면서 보는 것을 권장하는 편이다. 추천시스템과 관련된 지표에 대해서 설명했으니, 우선순위가 있는 추천시스템을 사용할 때 한번 적용해보기 바란다.
6. Reference
https://lamttic.github.io/2020/03/20/01.html
정보 검색(Information Retrieval) 평가는 어떻게 하는 것이 좋을까?(2/2)
data-analysis, machine-learning, recommender-system, and so on..
lamttic.github.io
https://medium.com/musinsa-tech/map-416b5f143943
무신사가 검색 품질을 관리하는 방법
mean Average Precision(mAP) — 검색 모델 평가 지표의 개념과 활용
medium.com
https://sungkee-book.tistory.com/11
[추천시스템] 성능 평가 방법 - Precision, Recall, NDCG, Hit Rate, MAE, RMSE
[추천시스템 시리즈] 2021.08.30 - [데이터과학] - [추천시스템] 비개인화 추천 알고리즘 - 인기도 기반 추천 2021.09.01 - [데이터과학] - [추천시스템] 성능 평가 방법 - Precision, Recall, NDCG, Hit Rate, MAE, RMSE
sungkee-book.tistory.com
'AI Study > Marketing&Recommend' 카테고리의 다른 글
| [CRM] 디지털 멀티 채널 마케팅 분석 방법 3가지 (0) | 2022.08.28 |
|---|---|
| [Process Mining] Process Mining이란? (0) | 2022.08.15 |
| [CRM] 01. CRM, CRM Marketing 에 대해서 (0) | 2022.07.30 |