2021.05.31 - [Study/NLP] - [NLP/자연어처리] ELMo(Embeddings from Language Models)
[NLP/자연어처리] ELMo(Embeddings from Language Models)
2021.05.26 - [Study/NLP] - [NLP/자연어처리] Seq2Seq(3) - 트랜스포머(Transformer)_Encoder [NLP/자연어처리] Seq2Seq(3) - 트랜스포머(Transformer)_Encoder 2021.05.24 - [Study/NLP] - [NLP/자연어처리] Seq..
everywhere-data.tistory.com
ELMo에 이어서 Pretrained 모델 중 하나인 GPT-1 에 대해서 이야기해보려 한다. 이는 OpenAI라고 하기도 한다.
1. GPT의 개요
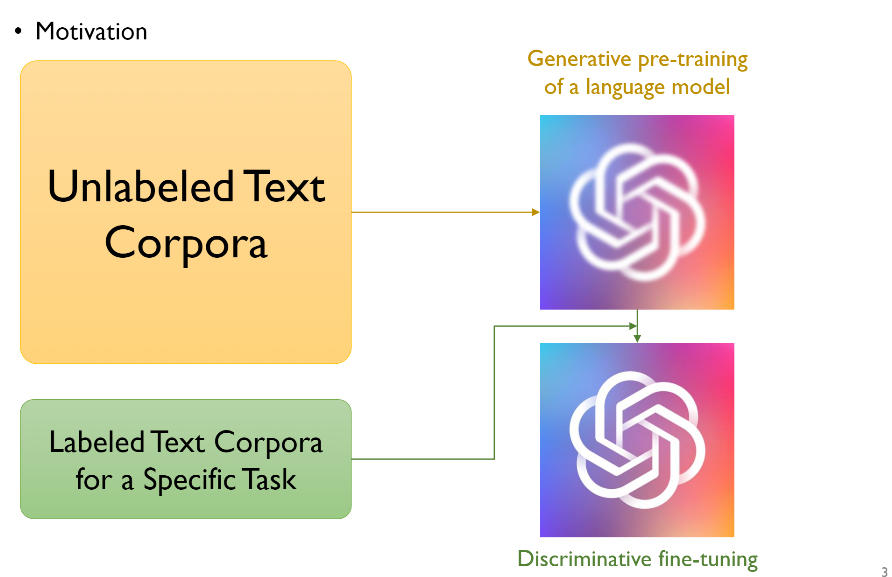
GPT의 개괄적인 개요는 ELMo와 비슷하다. 우리에겐 label이 매겨지지 않은 text들이 아주 많이 있다. (예를 들어 위키디피아 라던지, 책의 내용들을 카피할 수도 있다.) 이런 데이터들을 가지고 generative pre-training 언어모델, 즉 GPT모델을 사용해서 word embedding 모델을 만든 후, 실제로 우리가 정의한 label이 매겨진 데이터들의 task를 가지고 discriminative fine-tunning을 하는것이 GPT의 개요이다. 여기서 ELMo와의 차이점을 이야기하자면, LSTM이 아닌 Transformer의 Decoder part를 사용했다는 것이다.
2. GPT의 아키텍처

GPT와 ELMo의 차이는 위 슬라이드의 그림을 보면 알수 있듯이, ELMo는 forward와 backword 모델을 둘다 사용했지만, OpenAI GPT는 forward Transformer에서 masking했음을 알 수 있다.



GPT는 Transformer의 Decoder부분 중에서도 Multihead Masked self-Attention만을 사용하며, Encoder-Decoder Attention은 사용하지 않는다. 따라서, Multihead Masked self-Attentiond의 디코더를 여러개 쌓아서 학습을 하는 것이 GPT의 아이디어라고 할 수 있다.

여기서 주의할 것은, 원래 Transformer에서는 포지셔녈 인코딩(Positional Encoding)이라는 방법을 통해서 단어의 위치 정보를 표현했었다. 그래서 위치 자체에 대한 값은 학습이 아닌 정해진 값이었다. 그러나 GPT와 BERT에서는 위치 정보를 학습을 통해서 얻는 포지션 임베딩(Position Embedding)이라는 방법을 사용한다. 그 뒤의 방식은 Transformer와 동일하게 Word Embedding 값과 Position Embedding 값을 더해여 Decoder로 들어가게 된다.
3. GPT supervised fine-tunning
GPT를 이용해서 각 코퍼스에 대한 pretrain을 마쳤다면, 이를 이용해 supervised fine-tunning을 하는 것이 우리의 최종 목적이다.
코퍼스 C에 대한 label이 있는 데이터 셋이 있고, 토큰이 $x^I, ..., x^m$, 그 결과로 나온 label이 y라고 가정하자. input은 pre-train을 통해 나온 결과 $h_l^m$즉 가장 마지막 transformer의 m번째 단어의 activation값을 얻게 되고, 그 위에 linear layer를 추가해 최종 결과를 얻는 것이다. 그래서 언어 모델은 앞 단어를 보고 다음 단어를 예측하는 것이지만, GPT는 sequence length안의 token들 사이에 주어진 y에 대해서, transformer의 m번째 단어에 대한 마지막 hiddenstate의 결과벡터에 linear를 추가하고, softmax값을 취하여 최종 예측 확률을 구하는 것이다. 이에 대한 수식은 아래와 같다.
$$P(y|x^1, ..., x^m) = softmax(h_l^mW_y)$$
기울기를 최적화 하기 위한 목적함수는 다음과 같다.
$$L_2(C) = \sum_{(x, y)}logP(y|x^1, ..., x^m)$$
이때, ELMo와 잠깐 비교를 하자면, ELMo는 Language model에 대한 pre-train을 먼저 수행한 다음, downstream task에 대해 pretrain모델의 hidden state를 고정한 상태에서 각 layer의 가중치만 변경하여 task를 수행했지만, 논문에 의하면 GPT는 다르게 pre-train을 먼저 수행하여 $L_1(U)$에 대한 목적함수를 최대화시킨 후에, 각copus에 대해 $L_2(C) + \lambda \times L_1(C)$ 로 값을 업데이트해준다. 이에 대한 논문에서 이야기하는 이점은 supervised model에 대한 일반화(generalization)이 향상된다는 점, 그리고 학습 속도가 빨라진다는 점이다.
4. Task에 따른 GPT의 입력 방식

fine-tunning하는 task에 따라서 입력 구조의 형태가 달라지는데, 분류(Classification), 참거짓분류(Entailment), 유사도(Similarity), 다중선택(Multiple Choice)에 따라 각 방법이 달라진다. 신기했던 점은 하나의 코퍼스에 Delim이라는 구분자를 넣어서 문장 1과 문장 2를 구분하는 점이었다. 그 구분을 Transformer 연산을 통해 서로 다른 입장(?) 의 문장이라는 것을 알 수 있다.
5. 모델의 성능

위의 결과를 보며 성능에 대해 보자면, transformer + LM을 목적함수로 추가한 모델과 비교군으로 transformer + pretrain하지 않은 supervised model만 추가한 것, transformer + LM에 대한 목적함수를 제외한 것, transformer가 아닌 LSTM을 사용한 것을 비교했을 때, 데이터가 많을 때에는 LM모델을 사용하는 것이 성능이 더 좋지만, 데이터의 양이 적을 때에는 오히려 LM을 사용하지 않는 것이 더 도움이 된다.
'AI Study > NLP' 카테고리의 다른 글
| [NLP/자연어처리] Beyond BERT (1) | 2021.06.08 |
|---|---|
| [NLP/자연어처리] pre-trained model(3) - BERT(Bidirectional Encoder Representations from transformer) (0) | 2021.06.01 |
| [NLP/자연어처리] pre-trained model(1) - ELMo(Embeddings from Language Models) (0) | 2021.05.31 |
| [NLP/자연어처리] Seq2Seq4 - 트랜스포머(Transformer)_Decoder (0) | 2021.05.26 |
| [NLP/자연어처리] Seq2Seq(3) - 트랜스포머(Transformer)_Encoder (0) | 2021.05.26 |