반응형

* 위 강의노트는 패스트캠퍼스에서 주관하는 강의를 수강하고 작성한 노트입니다.
2.broadcasting 이해 및 활용하기
브로드캐스팅이란?
- shape이 같은 두 ndarray에 대한 연산은 각원소별로 진행
- 연산이 되는 두 ndarray가 다른 shape를 갖는 경우, 브로드캐스팅(shape을 맞춤) 후 진행
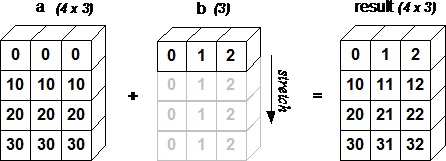
- 행렬이 맞지 않는 데이터를 행렬을 맞춰서 연산 진행!
-
뒷 차원에서부터 비교하여 shape이 같거나 차원 중 값이 1인 것이 존재하면 가능
-
shape이 같은 경우의 연산
x = np.arnage(9).reshape(3,3)
y = np.arange(9).reshape(3,3)
x + y[[ 0, 2, 4],
[ 6, 8, 10],
[14, 16, 18]]
- scalar(상수)와의 연산
x + 1 # 상수랑 연산하는 것은 어떤 것이든 연산이 가능[[1, 2, 3],
[4, 5, 6],
[7, 8, 9]]
- Shape이 다른 경우 연산
z = np.array([1, 2, 3])
x + z # 뒷 차원이 같은 것끼리의 연산
r = np.array([1, 2, 3, 4])
x + r # 뒷 차원이 같지 않으므로 Error((4,3) != (4, ))[[ 1, 3, 5],
[ 4, 6, 8],
[ 7, 9, 11]]
3.Boolean indexing으로 조건에 맞는 데이터 선택하기
- Boolean indexing
- ndarray 인덱싱 시, bool 리스트를 전달하여 True 인 경우만 필터링
- 브로드캐스팅을 활용하여 ndarray로부터 bool list 얻기
- 예) 짝수인 경우만 찾아보기
x = np.random.randint(1, 100, size = 100)
print(x)[42 13 19 4 46 18 54 65 78 71]
x % 2 == 0array([True, False, False, True, True, True, True, False, True, False])
- bool리스트를 인덱스로 전달
even_mask = x % 2 == 0
x[even_mask] # 조건이 참인 것만 추출
x[x % 2 == 0] # 조건이 참인 것만 추출array([42, 4, 46, 18, 54, 78])
- 다중 조건 사용하기
- 파이썬 논리 연산자인 and, or, not키워드 사용 불가
- & : AND
- | : OR
x % 2 == 0
x < 30
x[(x % 2 == 0) & (x < 30)] # 짝수이고 30보다 작은 수만 출력array([4, 18])
linalg 서브모듈 사용하여 선형대수 연산하기
np.linalg.inv
- 역행렬을 구할 때 사용
- 모든 차원의 값이 같아야 함
x = np.random.rand(3, 3)
y = np.linalg.inv(x) ## 역행렬 구하기. 정방행렬이어야만 가능
x @ y # 행렬곱 진행
np.matmul(x ,y) # 위 함수와 같음array([[1., 0., 0.],
[0., 1., 0.],
[0., 0., 1.]])
- np.linalg.solve
- Ax = B 형태의 선형대수식 솔루션을 제공
- 예제 ) 호랑이와 홍합의 합 : 25 호랑이 다리와 홍합 다리의 합은 64
- x + y = 25
- 2x + 4y = 64
A = np.array([[1, 1], [2, 4]])
B = np.array([25, 64])
x = np.linalg.solve(A, B)
print(x) # 호랑이 8마리, 홍합 7마리
np.allclose(A@x, B) # 정답이 맞는지 확인[18. 7.]
matplotlib을 활용하여 ndarray데이터로 다양한 그래프 표현하기
import matplotlib.pyplot as plt
%matplotlib inline # 그래프가 주피터 안에서 이루어진다그래프 데이터 생성
x = np.linespace(0, 10, 11)
y = x**2 + x + 2 + np.random.randn(11)그래프 출력하기
- plot 함수(선 그래프), scatter(점 그래프), hist(히스토그램) 등 사용
- 함수의 parameter 혹은 plt의 다른 함수로 그래프 형태 및 설정을 변경 가능
- 기본적으로, x, y에 해당하는 값이 필요
plt.plot(x, y) # x와 y에 대한 선형 그래프 생성
plt.scatter(x, y) # x와 y에 대한 scatter plot 생성그래프에 주석 추가
- x, y 축 및 타이틀
- grid 추가
- x, y축 범위 지정
plt.xlabel('X values') # x축 제목
plt.ylabel('Y values') # y축 제목
plt.title('X-Y relation') # 그래프 제목
plt.grid(True) # grid 그리기
plt.xlim(0, 20) # x축 limit 정하기
plt.ylim(0, 20) # y축 limit 정하기
plt.plot(x, y)plot 함수 parameters
- 그래프의 형태에 대한 제어 가능
- 그래프의 색상 변경
plt.plot(x, y, 'y') # 마지막 파라미터에 색깔입력
plt.plot(x, y, '#ffffff') # RGB코드로도 가능- 그래프 선 스타일 변경
- 그래프 두께 변경
plt.plot(x, y, '-.') # 점선으로 구현
plt.plot(x, y, 'r^') # 빨간색 세모로 구현
plt.plot(x, y, '-.', linewidth = 3) # 두께 조절subplot으로 여러 그래프 출력하기
- subplot 함수로 구획을 구별하여 각각의 subplot에 그래프 출력
plt.subplot(2, 2, 1) # 총 4개의 2행 2열 plot 생성. 그중 첫번 째 plot 명시
plt.plot(x, y, 'r')
plt.subplot(2, 2, 1) # 2번째 plot 명시
plt.plot(x, y, 'g')
plt.subplot(2, 2, 1) # 3번째 plot 명시
plt.plot(x, y, 'b')
plt.subplot(2, 2, 1) # 3번째 plot 명시
plt.plot(x, y, 'k')hist 함수
- histogram 생성
- bins로 histogram bar 개수 설정
data = np.random.randint(1, 100, size = 200)
plt.hist(data, bins = 10) # 막대그래프 10개로 히스토그램 생성반응형
'AI Study > ML_Basic' 카테고리의 다른 글
| 머신러닝과 데이터 분석 A-Z 올인원 패키지 - 데이터 분석을 위한 Python(Pandas) – (2) (0) | 2020.09.30 |
|---|---|
| 머신러닝과 데이터 분석 A-Z 올인원 패키지 - 데이터 분석을 위한 Python(Pandas) – (1) (0) | 2020.09.30 |
| 머신러닝과 데이터 분석 A-Z 올인원 패키지-데이터 처리를 위한 Python(Numpy) – (1) (0) | 2020.09.30 |
| 머신러닝과 데이터 분석 A-Z 올인원 패키지-데이터 수집을 위한 Python(2) (0) | 2020.09.10 |
| 머신러닝과 데이터 분석 A-Z 올인원 패키지 - 데이터 수집을 위한 Python(1) (0) | 2020.09.10 |