Tensor Manipulation(텐서 조작)¶
Pytorch Basic Tensor Manipulation¶
- Vector, Matrix and Tensor
- Numpy Review
- Pytorch Tensor Allocation
- Matrix Multiplication
- Other Basic Ops
Vector, Matrix and Tensor¶
- 스칼라(Scaler) : 차원이 없는 값(0차원)
- 벡터(Vector) : 1차원으로 이루어져있는 값
- 행렬(Matrix) : 2차원으로 이루어져 있는 값
- 텐서(Tensor) : 3차원 이상으로 이루어져 있는 값
Pytorch Tensor Shape Convention¶
텐서의 크기 표현하는 방법
-
2D Tensor (Typical Simple Setting)
- |t| = (atchsize,dim)
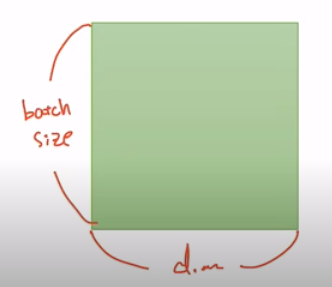
-
3D Tensor (Typical Computer Vision, 이미지 데이터 분석)
- |t|= (batchsize,width,heigbatchsize,width,height) )
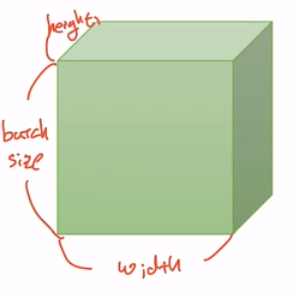
-
3D Tensor (Typical Natural Language Processing, NLP 저연어 처리 분석)
- |t|= (batchsize,length,dim)
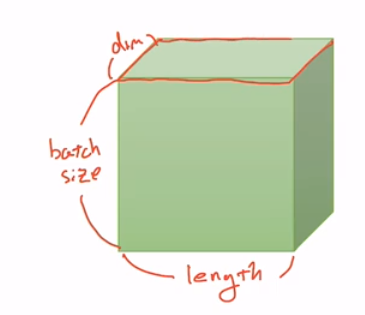
import numpy as np
import torch
1D Array with Numpy¶
t = np.array([0., 1., 2., 3., 4., 5., 6. ])
print(t)
print('Rank of t : ', t.ndim) ## 몇개의 차원으로 되어있는가?
print('Shape of t : ', t.shape) ## 어떤 형태를 가지고 있니?
print('t[0], t[1], t[-1] = ', t[0], t[1], t[-1]) ## Element. 원하는 문자열 추출
print('t[2:5], t[4:-1] = ', t[2:5], t[4:-1]) ## Slicing. 원하는 문자열 길이만큼 자르기
print('t[:2], t[3:] = ', t[:2], t[3:]) ## Slicing
2D Array with Numpy¶
t = np.array([[1., 2., 3.], [4., 5., 6.], [7., 8., 9.], [10., 11., 12.]])
print(t)
print('Rank of t : ', t.ndim) ## 몇개의 차원으로 되어있는가?
print('Shape of t : ', t.shape) ## 어떤 형태를 가지고 있니?
1D Array with Pytorch¶
t = torch.FloatTensor([0., 1., 2., 3., 4., 5., 6. ]) ## numpy와 작동방식이 동일
print(t)
print(t.dim()) # rank
print(t.shape) # shape
print(t.size()) # shape
print(t[0], t[1], t[-1]) # Element
print(t[2:5], t[4:-1]) # Slicing
print(t[:2], t[3:]) # Slicing
2D Array with Pytorch¶
t = torch.FloatTensor([[1., 2., 3.],
[4., 5., 6.],
[7., 8., 9.],
[10., 11., 12.]
])
print(t)
print(t.dim()) # rank
print(t.size()) # shape
print(t[:, 1])
print(t[:, 1].size())
print(t[:, :-1])
Broadcasting¶
파이토치를 어떻게 다루는가?
- 행렬을 다룰 때의 규칙
- 덧셈이나 뺄셈을 할 때에는 애초에 두 텐서 간의 크기가 같아야 한다.
- 행렬 곱을 수행할 때 마지막 차원과 첫번째 차원이 일치해야 한다.
그러나 다른 형태의 행렬을 불가피하게 사칙연산을 수행해야 하는 경우가 있는데, 이 때 broadcasting을 통해서 자동적으로 size를 맞춰 진행할 수 있다.
# Same shpae
m1 = torch.FloatTensor([[3, 3]]) ## 1X2 matrix
m2 = torch.FloatTensor([[2, 2]]) ## 1X2 matrix
print(m1 + m2)
# Vector + scalar
m1 = torch.FloatTensor([[1, 2]])
m2 = torch.FloatTensor([3]) # 3 -> [[3, 3]]
print(m1 + m2)
# 2 X 1 Vectpr + 1 X 2 Vector
m1 = torch.FloatTensor([[1, 2]]) ## [[1, 2]] -> [[1, 2],[1, 2]]
m2 = torch.FloatTensor([[3], [4]]) ## [[3], [4]] -> [[3, 3],[4, 4]]
print(m1 + m2)
Broadcasting은 자동으로 실행되는 것이기 때문에 실수를 하지는 않는지 조심해서 확인해야한다.
Multiplication vs Matrix Multiplication¶
딥러닝은 행렬 곱 연산을 굉장히 많이 사용하는 알고리즘이다. 그래서 행렬곱을 구현하는 것이 매우 중요하다.
- 일반 matrix 곱 : 각 원소끼리의 곱. 일반적으로 행렬의 형태가 같아야 곱셈이 되지만, 행렬의 형태가 다른 경우 broadcasting 되어서 곱해진다.
- 행렬 곱(내적, inner product) : 가장 마지막의 차원과 첫번째의 차원이 같아야 행렬곱이 가능해짐.
print()
print('-------------')
print('Mul vs Matmul')
print('-------------')
m1 = torch.FloatTensor([[1, 2], [3, 4]])
m2 = torch.FloatTensor([[1], [2]])
print('Shape or Matrix 1 : ',m1.shape) # 2 X 2
print('Shape or Matrix 2 : ',m2.shape) # 2 X 1
print(m1.matmul(m2)) # 2 X 1
m1 = torch.FloatTensor([[1, 2], [3, 4]])
m2 = torch.FloatTensor([[1], [2]])
print('Shape or Matrix 1 : ',m1.shape) # 2 X 2
print('Shape or Matrix 2 : ',m2.shape) # 2 X 1
print(m1.mul(m2))
Mean¶
행렬의 평균 구하기
t = torch.FloatTensor([1, 2])
print(t.mean())
# LongTensor에 대해서는 평균을 구할 수 없다.
# Can't use mean() on integers
t = torch.LongTensor([1, 2])
try :
print(t.mean())
except Exception as exc:
print(exc)
우리가 원하는 차원에 대해서만 평균을 구할 수 있다.
You can also use t.mean for higer rank tensors to get mean of all elements or mean by particuler dimension.
t = torch.FloatTensor([[1, 2], [3, 4]])
print(t)
print(t.mean()) # 모든 원소값의 평균
print(t.mean(dim = 0)) # 0차원을 없애겠어. 2 x 2 -> 1 x 2
print(t.mean(dim = 1)) # 1차원을 없애겠어. 2 x 2 -> 2 x 1
print(t.mean(dim = -1)) # 가장 마지막 차원을 없애겠어
sum¶
t = torch.FloatTensor([[1, 2], [3, 4]])
print(t)
print(t.sum()) # 모든 원소값의 합
print(t.sum(dim = 0)) # 0차원을 없애겠어. 2 x 2 -> 1 x 2
print(t.sum(dim = 1)) # 1차원을 없애겠어. 2 x 2 -> 2 x 1
print(t.sum(dim = -1)) # 가장 마지막 차원을 없애겠어
Max and Argmax¶
- Max : 어떤 텐서나 행렬에 대해 가장 큰 값을 찾아주는 것을 말한다.
- Argmax : max값의 index를 리턴해주는 경우
t = torch.FloatTensor([[1, 2], [3, 4]])
print(t)
print(t.max()) # Returns one value : max
print(t.max(dim = 0)) # max값과 그에 해당하는 index를 알려줌
print('Max : ', t.max(dim = 0)[0])
print('Argmax : ', t.max(dim = 0)[1])
View (Reshape)¶
view는 numpy에서 reshape라는 함수와 같은 역할을 한다.
Reshape를 다시 만들어준다는 의미와 같다.
t = np.array([[[0, 1, 2],
[3, 4, 5]],
[[6, 7, 8],
[9, 10, 11]]])
ft = torch.FloatTensor(t)
print(ft.shape)
print(ft.view([-1, 3])) # 두개의 차원인데, 뒷 차원만 3으로 맞춰줘
print(ft.view([-1, 3]).shape)
print(ft.view([-1, 1, 3])) # 3개의 차원인데 2번째, 3번재 dim을 1, 3 으로 맞춰줘
print(ft.view([-1, 1, 3]).shape)
Squeeze¶
기본적으로 view와 비슷하나 자동으로 내가 원하는 dimension의 element 개수가 1인 경우에 해당 demension을 없애줌
ft = torch.FloatTensor([[0],[1],[2]])
print(ft)
print(ft.shape)
print(ft.squeeze())
print(ft.squeeze().shape)
Unsqueeze¶
내가 원하는 dimension에 1을 넣어주는 함수
ft = torch.Tensor([0, 1, 2])
print(ft.shape)
print(ft.unsqueeze(0)) ## 괄호 안에 차원의 rank를 넣어줌
print(ft.unsqueeze(0).shape) # 3 -> 1 x 3
print(ft.view(1, -1)) # 두개의 차원을 만들 건데, 0번째 차원의 dimension은 1이야.
print(ft.view(1, -1).shape) # 3 -> 1 x 3
print(ft.unsqueeze(1)) # 1번째 차원의 dimeansion에 1을 넣어줌
print(ft.unsqueeze(1).shape) # 3 -> 3 x 1
print(ft.unsqueeze(-1)) # 가장 마지막 차원에 1을 넣어줌
print(ft.unsqueeze(-1).shape) # 3 -> 3 x 1
Type Casting¶
텐서의 타입을 바꿔주는 것
#integer 형태의 tesnor
lt = torch.LongTensor([1, 2, 3, 4])
print(lt)
print(lt.float())
# Boolean 형태의 tensor
bt = torch.ByteTensor([True, False, False, True])
print(bt)
print(bt.long())
print(bt.float())
Concatenate¶
두개의 텐서를 이어붙이는 함수
x = torch.FloatTensor([[1, 2], [3, 4]]) # 2 x 2
y = torch.FloatTensor([[5, 6], [7, 8]]) # 2 x 2
print(torch.cat([x, y], dim = 0)) # 0번째 차원을 기준으로 concatenate
print(torch.cat([x, y], dim = 1)) # 1번째 차원을 기준으로 concatenate
Stacking¶
concatenate와 비슷한 함수. 몇가지를 함축시켜놓음
# x, y, z shape : (2,)
x = torch.FloatTensor([1, 4])
y = torch.FloatTensor([2, 5])
z = torch.FloatTensor([3, 6])
print(torch.stack([x, y, z]))
print(torch.stack([x, y, z], dim = 1))
# 위 stack 함수를 cat으로 구현하면 아래와 같음
print(torch.cat([x.unsqueeze(0), y.unsqueeze(0), z.unsqueeze(0)], dim = 0))
Ones and Zeros¶
정의한 dimension 만큼 원소가 0 또는 1로만 이루어진 행렬을 생성하는 함수
x = torch.FloatTensor([[0, 1, 2], [2, 1, 0]])
print(x)
print(torch.ones_like(x)) ## x와 동일한 shape의 0으로만 이루어진 행렬 생성
print(torch.zeros_like(x)) ## x와 동일한 shape의 1로만 이루어진 행렬 생성
In-place Operation¶
- inplace 선언문으로 메모리에 새로 선언하지 않고 기존 메모리 텐서에 정답 값을 넣는 연산
- 함수 뒤에 '_'를 붙여준다.
x = torch.FloatTensor([[1, 2], [3, 4]])
print(x.mul(2.))
print(x)
print(x.mul_(2.)) ## in-place operation
print(x)
출처 :www.edwith.org/boostcourse-dl-pytorch/lecture/42283/
[LECTURE] Lab-01-2 Tensor Manipulation 2 : edwith
학습목표 지난 시간에 이어서 텐서 조작(Tensor Manipulation)에 대해 계속 알아본다. 핵심키워드 텐서(Tensor) 넘파이(NumPy) 텐서 조작(Tensor Man... - 양동현
www.edwith.org
'AI Study > DL_Basic' 카테고리의 다른 글
| [파이토치로 시작하는 딥러닝 기초]05_ Logistic Regression (0) | 2020.12.22 |
|---|---|
| [파이토치로 시작하는 딥러닝 기초]04.02_Loading Data (0) | 2020.12.21 |
| [파이토치로 시작하는 딥러닝 기초]04.01_Multivariable_Linear_regression (0) | 2020.12.21 |
| [파이토치로 시작하는 딥러닝 기초]03_Deeper Look at Gradient Descent (0) | 2020.12.21 |
| [파이토치로 시작하는 딥러닝 기초]02_Linear Regression (0) | 2020.12.21 |