![[NLP/자연어처리] 자연어처리와 딥러닝의 역사, 발전과정](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2Fsxee3%2Fbtq4tAKDIRu%2F140DS4bVZlYxpVnj4c2jy1%2Fimg.jpg)
[NLP/자연어처리]
해당 내용은 김기현의 자연어 처리 딥러닝 캠프 파이토치편을 읽으며 발췌 및 정리한 내용입니다.
1. 개요
1.1 자연어처리와 딥러닝의 역사
자연어처리(natural language processing, NLP)는 인공지능의 한 분야로, 사람의 언어를 컴퓨터가 알아듣도록 처리하는 인터페이스의 역할을 한다. 자연어 처리 기술을 사용하는 대표적인 응용분야는 아래와 같다.
- 감성분석과 같은 대량의 텍스트를 이해하고 정형화 하는 작업(clustering, classification 등)
- 애플의 시리(Siri) 와 같이, 사용자의 의도를 파악하고 대화를 하거나 도움을 주는 작업(질의응답)
- 요약(summarization), 기계번역(machine translation)과 같은 작업
- 사용자로부터 입력을 받아 사용자가 원하는 것을 검색 및 답변주는 작업
자연어처리를 공부하기 위해서는 최신기술을 무작정 공부하는 것이 아니라 그 이전의 기술들을 이해하고, 무엇이 문제였으며, 최신 기술이 어떤 돌파구를 마련했는지 파악하는 것이 중요하다.
딥러닝에서 가장 먼저 두각을 나타낸 곳은 이미지 분류 문제인 이미지넷 대회였고, 상용화 부문에서 빛을 본 분야는 음성인식 쪽이었다. 자연어처리는 이들에 비해 상대적으로 가장 나중에 두각이 드러났다. 아무래도 언어의 다양성과 동시에 단어간의 순서 및 상호 정보가 반영된다는 점이 큰 장벽일 것이다. 그러나 결국 어텐션 메커니즘의 등장으로 end-to-end방식의 딥러닝에 의해 지연어처리는 정복되었다.
[2010년 이전의 딥러닝]
1950년대와 1980년대에도 인공지능은 대유행을 맞이했었다. 그러나 그에 따른 빙하기도 있었다. 1950년대에는 XOR문제로 하나의 Linear 모델로는 XOR문제를 풀 수 없다는 문제 때문에 인공지능이 빙하기를 맞이했으나, 1980년대 역전파 알고리즘이 제안되어 문제가 해결되었다. 그러나 여러 한계점이 드러나면서 두번째 침체기를 맞았다. 그래서 많은 사람들이 인공신경망에 대해 부정적인 시각을 가지고 있을 때, 2006년에 제프리 힌튼 교수는 딥 빌리프 네트워크라 불리는 심층 신뢰 신경망(Deep Belief Network, DBN)을 통해 여러 은닉층을 효과적으로 사전훈련 시키는 방법을 제안했다.
[이미지 분류]
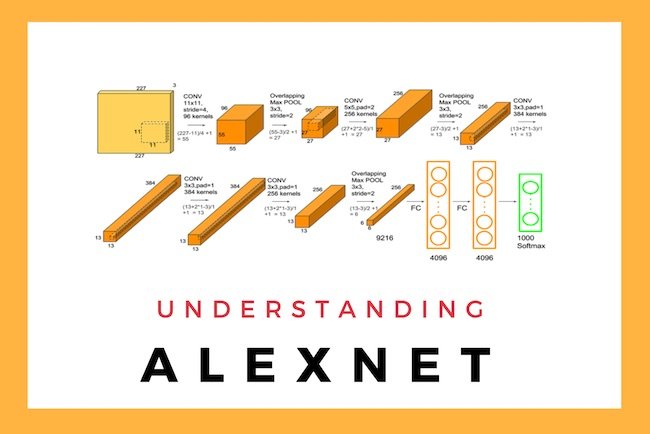
2012년 이미지넷에서 인공신경망을 이용한 AlexNet은 경쟁자들을 큰 차이로 따돌리고 우승하며 딥러닝 시대의 서막을 올렷다. Alexnet은 여러층의 합성곱계층을 쌓아서 네트워크 구조를 만들어 다른 경쟁자들과 확연한 실력 차이를 보여주었다.
그 이후 이미지넷 대회에서는 거의 모든 참가자가 딥러닝을 이요해서 알고리즘을 구현했다. 그 과정에서 ResNet의 Residual Connection 또한 개발되었다.
이런 연구와는 별개로 실생활에서 이미지 분류 문제는 분류 자체의 난도가 워낙 높아 여전히 어려움이 남아있다. 따라서 산업계에서는 이와 관련해 많은 연구개발을 하는 중이다.
[음성인식]

음성인식은 2000년대에 들어 큰 정체기를 맞이하고 있었다. GMM을 통해 음소를 인식하고 이를 hidden Markov model(HMM)을 통해 시퀀셜 정보를 반영해 학습하여 만든 음향모델(acoustic model, AM)과 n-gram기반의 언어모델(language model, LM)을 결합한 자동음성인식(ASR)시스템은 너무 복잡한 구조로 성능에 한계를 보이고 있었다.
그러나 GMM 모델을 DNN으로 대체하니 십수년간의 정체기를 단숨에 뛰어넘는 혁명이 발생했다. 그리고 점처 음향모델 전체를 LSTM으로 대체하게 되었고, 현재는 end-to-end 방식이 성과를 내고 자리잡고 있다.
[기계번역]
딥러닝 이전의 기계번역은 통계 기반 기계번역(statistic machine model, SMT)이 지배하고 있었다. 통계 기반 기계번역은 규칙 기반 기계번역 방식에 비해 언어 간 확장이 용이한 장점이 있었고, 성능도 뛰어났지만, 음성인식처럼 매우 복잡한 구조를 지니고 있었다.
2014년 이후 seq2seq 모델 구조가 소개되면서 end-to-end신경망 기반의 기계번역 시대가 열리게 되었다. 그 기반으로 어텐션 메커니즘이 제안되면서 기계번역은 신경망 기계번역으로 대통합이 이루어지게 되었다.
[생성모델 학습]
딥러닝은 패턴 분류 성능에서 타 알고리즘에 비해 매우 압도적인 모습을 보여주어서 다른 단순한 분류문제는 금방 정복되었다. 이에 연구자들은 생성모델학습이라는 흥미거리를 찾았다.
기존의 판별 모델 학습은 데이터 X가 주어졌을 때 알맞은 레이블 Y를 찾아내는 것에 집중했다면, 생성모델은 데이터 X 분포 자체를 배우는 것에 집중한다. 예를 들어, 기존에는 사람의 얼굴이 여자냐, 남자냐에 집중했다면, 이제는 사람의 얼굴 자체를 보고 묘사할 수 있는 모델을 훈련하고자 했다.
이러한 과정에서 적대적학습이나, variational autoencoder(VAE)등이 주목받게 되었는데, 이러한 연구는 여전히 현재진행형이며, 많은 문제가 남아있다.
[자연어처리의 패러다임 변화]
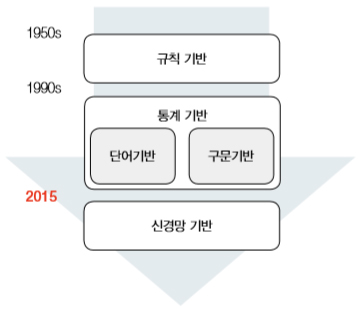
딥러닝 이전의 자연어처리 애플리케이션의 구조는 여러 단계의 모듈로 구성되어 디자인이 복잡하고 구현 및 시스템 구성이 어려웠다. 게다가 각각의 모듈이 완벽하게 동작할 수 없어서 각기 발생한 오차가 중첩 및 가중되어 전파되는 오차의 전파 현상의 문제도 발생했다. 그러나 딥러닝이 들어오기 시작하면서 end-to-end모델로 대체되게 되었다.
딥러닝이 자연어 처리에서도 주류가 되면서 기존의 접근 방식을 탈피한 여러가지 변화들이 나타나기 시작했다.사람의 언어는 불연속적인 이산 심벌로 이루어져 있다. 따라서 기본적으로 모든 단어나 토큰은 서로 다른 심벌이라고 볼 수 있고, 기존의 전통적인 자연어 처리에서는 불연속적인 심벌로 데이터를 취급했다. 이러한 심벌릭 기반 접근 방법은 데이터를 보고 이해하기 쉽다는 장점이 있지만, 모호성이나 유의성을 다루기에는 어려움을 겪었다.
그러나 word2vec과 같은 단어 임베딩을 통해서 단어를 연속적인 벡터로 나타내게 되었다. 이러한 딥러닝 기반의 접근방법은 직접적인 해석은 비록 어려워졋지만 모호성과 유의성 문제를 잘 해결할 수 있게 되었다. 또한 딥러닝의 장점을 잘 살려 end-to-end모델을 구현함으로 더욱 높은 성능을 뽑을 수 있게 되었다.
| 심볼릭 기반 접근 방법 | 신경망 기반 접근방법 |
| 지식의 표현 방법 - 단어, 관계 , 템플릿 - 고차원, 이산적, 희소 벡터 형태 |
지식의 표현 방법 - 간소화 및 일반화된 지식 그래프 - 저차원, 연속적, dense한 벡터 형태 |
| 추론 - 거대한 지식 그래프로 인한 속도 감소 - 키워드 또는 템플릿 매칭에 민감함 |
추론 - 적은 메모리를 요구하며 빠르게 동작함 - 키워드 또는 템플릿 매칭에 강인함 |
| 장점 - 사람이 인지하기 쉽다. - 디버그가 용이하다 단점 - 연산 속도가 느리다 - 모호성과 유의성에 취약함 |
장점 - 연산 효율이 높고 속도가 빠르다 - 모호성과 유의성에 강인하다 단점 - 사람이 인지하기 어렵다 - 디버깅이 어렵다 |
1.2 자연어 처리의 어려움
다른 분야와 같이 자연어처리도 어려움을 가지고 있다. 자연어처리가 어려운 이유들을 짚어보려고 한다.
[모호성]
한국어 뿐 아니라 다양한 언어들 사이에서는 중의어가 있기도 하고, 동의어가 있기도 하다. 그래서 하나의 문장만 보고서는 문장 내 정보의 부족으로 모호성이 발생할 수 있다. 책에서 간단하게 예기가 있었다.
| 원문 | 나는 철수를 안때렸다. |
| 해석#1 | 철수는 맞았지만, 때린 사람이 나는 아니다 |
| 해석#2 | 나는 누군가를 때렸지만, 그게 철수는 아니다. |
| 해석#3 | 나는 누군가를 때린 적도 없고, 철수도 맞은 적도 없다 |
사람의 경우에는 이렇게 생략된 정보로 구멍을 쉽게 메울 수 있지만 컴퓨터는 이런한 문제들이 매우 어렵게 다가온다고 한다.
[다양한 표현]

개가 공중에 던져진 원반을 잡기 위해 달려가는 사진이 있다고 가정해보자. 이 사진을 사람에게 한 문장으로 묘사해달라고 한다면 다양한 표현이 나올 것이다.
- 골든 리트리버가 잔디밭에서 공중의 원반을 향해 달려가고 있습니다.
- 원반이 날아가는 방향으로 개가 뛰어가고 있습니다.
- 개가 잔디밭에서 원반을 쫓아가고 있습니다.
하지만 알고보면 다 같은 사진을 묘사하는 것이고 그 의미는 같다고 볼 수 있다. 문장의 표현 형식이 다양하기 때문이다. 이러한 문제들이 자연어처리 문제의 어려움을 가중시킨다.
[불연속적인 데이터]
자연어 처리의 단어나 토큰은 불연속적인 데이터이므로 과거에는 비교적 처리가 쉬웠다. 그러나 딥러닝(인공신경망)에 적용하려면 연속적인 값으로 바꾸어주어야했다. 최근에는 단어 임베딩이 그 역할을 훌륭히 수행하고 있다. 그러나 아래와같은 몇가지 제약은 여전히 존재한다.
- 차원의 저주
불연속적인 데이터라 많은 종류의 데이터를 표현하려면 단어만큼의 엄청난 차원이 필요하다. 즉, 각 단어를 불연속적인 심벌로 다룬 만큼, 어휘의 크기만큼의 차원이 있는 것이나 마찬가지였다. 이런한 sparseseness문제를 해결하기 위해 단어를 적절히 segmentation 하는 등 여러가지 노력이 필요했다. 단어 임베딩으로 차원축소하는 것으로 이문제는 해결했다.
- 노이즈와 정규화
단어는 불연속적인 데이터기 때문에 값 하나가 바뀔 때 의미의 변화가 훨씬 크다. 띄어쓰기나 어순의 차이로 인한 정제의 이슈 등도 자연어 처리에 큰 어려움이 될 수 있다.
1.3 자연어 처리의 어려움
대체로 한국어 자연어처리가 영어 자연어치보다 어렵다고들 한다. 그 이유에 대해서 알아보고자 한다.
[교착어]
한국어는 교착어에 속한다. 어순에 다라 단어의 문법적 기능이 정해지는 형태와 같은 영어와 다르게, 어간에 접사가 붙어 단어를 이루고 의미와 문법적 기능이 정해지는 것이다. 따라서 같은 의미의 동사인데도 접사가 무엇이냐에 다라 다양한 결과가 나올 수 있다.
[띄어쓰기]
한국어는 띄어쓰기에 맞춰서 발전해온 언어가 아니다보니 사람마다 띄어쓰기를 하는 것이 다를 뿐더러 띄어쓰기가 아예 없어도 해석이 되는 경우가 많다. 그래서 추가적 분절을 통해 띄어쓰기를 정제해주는 과정이 필요하다.
[평서문과 의문문]
영어에서는 의문문으로 바뀔 경우 단어의 어순이 바뀐다. 그러기 때문에 물음표를 쓰지 않아도 의문문인 것을 알 수 있다. 그러나 한국어는 같은 형태의 문장을 가지고 마지막 물음표가 붙어야만 의문문으로 알 수 있는 경우가 많다. 그렇기 때문에 자연어처리가 어려운 경우가 발생한다.
[주어 생략]
영어는 기본적으로 명사가 굉장히 중요하여 주어가 생략되는 경우가 거의 없다. 그러나 한국어는 동사를 중요시하여 주어가 생략되는 경우가 많다. 그래서 문장의 정확한 의미를 파악하기 어려운 경우가 많다.
[한자 기반의 언어]
한국어는 한자의 영향을 많이 받은 언어라 각 글자가 의미를 지니고 있고 그것이 합쳐져 단어의 뜻이 되는 경우가 많다. 그러나 이것을 한글인 표음문자로 표현하면서 정보의 손실이 생긴다. 음으로만 표현되어있는 한글이 무슨 의미를 가지고 있는지 알기 어렵기 때문이다.
1.4 자연어처리의 최근 동향
요즘의 자연어처리 최근 동향에 대해서 이야기 해보고자 한다.
2010 - RNN을 활용한 언어 모델을 시도하여 기존 n-gram 기반 언어 모델의 한계를 극복하고자 했다. 결국 n-gram의 결합을 통해 더 나은 성능의 언어모델을 만들 수 있었지만 구조적 한꼐와 높은 연산량으로 더 큰 성과를 거둘 수는 없었다.
2013 - 토마스 미르코프의 word2vec으로 단어들을 잠재공간에 효과적으로 투사시켜서 자연어처리 문제에 대한 딥러닝 활용의 신호탄을 쏘아올렸다.
2014 - RNN을 통해서만 자연어처리를 해결해야한다는 고정관념이 지배할 대, 윤 킴은 CNN을 활용한 텍스트 분류 모델을 제시하면서 성능을 더욱 극대화시켰다. 또한 seq2seq 발표에 이어서 어텐션(attention)기법이 개발되어 성공적으로 기계번역에 적용되면서 큰 성과를 거둔다. 이에 따라 자연어처리 분야는 자연어 생성까지 가능해지는 지경에 올랐다.
'Study > NLP' 카테고리의 다른 글
| [NLP/자연어처리] 자연어처리 전처리(4) - 토치텍스트(TorchText) (0) | 2021.05.13 |
|---|---|
| [NLP/자연어처리] 자연어 처리 전처리(3) - 단어집합(Vocabulary), 패딩 (4) | 2021.05.12 |
| [NLP/자연어처리 ]자연어 처리 전처리(2) - 분절(토큰화) 라이브러리 소개 (0) | 2021.05.11 |
| [NLP/자연어처리] 자연어 처리 전처리(1) - 코퍼스와 텍스트 정제 (0) | 2021.05.10 |
| [NLP/자연어처리] 자연어처리 관련 자료 모음 (1) | 2021.05.07 |