Study/NLP

[NLP/자연어처리] 이전의 자연어처리 방법론 - Word Embedding 과 Skip-Gram
오늘의 포스팅은 Bert와 같은 pretrained language model 이 나오기 전 자연어처리 문제를 어떻게 해결했는지에 대한 이야기를 포스팅해보려고 한다. 이전에 비슷한 내용의 포스팅을 한적이 있는데, 그 내용을 정리하는 차원으로 포스팅을 해보려고 한다. 2021.05.14 - [Study/NLP] - [NLP/자연어처리] 단어의 표현(1) - 원핫인코딩과 워드투벡터(Word2Vec) [NLP/자연어처리] 단어의 표현(1) - 원핫인코딩과 워드투벡터(Word2Vec) 해당 내용은 김기현의 자연어 처리 딥러닝 캠프 파이토치편 및 Pytorch로 시작하는 딥러닝 입문읽으며 발췌 및 정리하였으며, 필요에 따라 추가로 검색하여 내용을 보충했습니다. 이전 글 참고 everywhere-data.tisto..

[NLP/자연어처리] Self-supervised Learning
이번 포스팅에서는 Supervised learning과 Unsupervised learning, 그리고 Self supervised learning에 대해 설명해보고자 한다. 보통 머신러닝/딥러닝을 공부하는 사람들에게 지도학습과 비지도학습에 대한 이야기는 머신러닝의 기초이므로 익히 들어왔을 것이다. 이에 대해서는 간단하게 요약만 하고 넘어가며, Self supervised learning에 대해 조금 더 자세히 이야기해 보도록 하자. 1. Supervised Learning(지도학습) 지도학습은 X값들을 가지고 Y의 값을 예측하는, 즉 정답이 존재하는 데이터에 대해 학습하는 것을 말한다. 사전에 사용자가 만들어놓은 labeled 데이터에 대해 학습을 진행하며, 입력값 X와 출력값 Y 사이의 관계를 학습하..
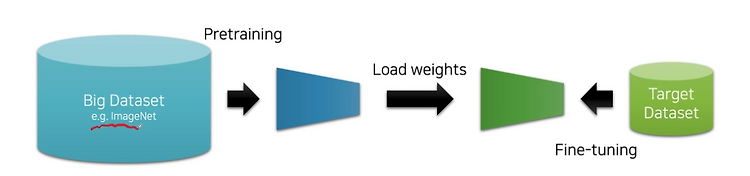
[NLP/자연어처리] Transfer Learning(전이학습)에 대한 소개
자연어 처리 관련 이론적 공부를 좀 더 깊게 하고자, 패스트캠퍼스의 강의를 수강중이다. 이번에는 관련 강의를 들으며 간략하게 요약 겸 복습을 하나씩 해보고자 한다. Transfer Learning(전이학습)이란? 리가 하나의 프로젝트를 위해 모델을 생성할 때 사용할 수 있는 데이터는 한정적이다. 각 데이터마다 레이블링을 진행하는데에 대한 인력비가 비쌀 뿐 아니라 시간도 오래걸리기 때문이다. 그래서 나온 대안이 대량의 데이터로 미리 학습을 진행하여 그 분야에 대한 일반화를 진행한 후에, 소수의 데이터로 더 집중적으로 학습하는 것이다. transfer learning, 즉 전이학습이란 빅데이터를 이용하여 사전학습을 진행(Pretraining)하고, 우리가 가지고 있는 특정한 일(task)의 데이터를 가지고 ..

[NLP/자연어처리] Beyond BERT
2021.06.01 - [Study/NLP] - [NLP/자연어처리] pre-trained model(3) - BERT(Bidirectional Encoder Representations from transformer) [NLP/자연어처리] pre-trained model(3) - BERT(Bidirectional Encoder Representations from transformer) 2021.05.31 - [Study/NLP] - [NLP/자연어처리] pre-trained model(1) - ELMo(Embeddings from Language Models) [NLP/자연어처리] ELMo(Embeddings from Language Models) 2021.05.26 - [Study/NLP] - [N..

[NLP/자연어처리] pre-trained model(3) - BERT(Bidirectional Encoder Representations from transformer)
2021.05.31 - [Study/NLP] - [NLP/자연어처리] pre-trained model(1) - ELMo(Embeddings from Language Models) [NLP/자연어처리] ELMo(Embeddings from Language Models) 2021.05.26 - [Study/NLP] - [NLP/자연어처리] Seq2Seq(3) - 트랜스포머(Transformer)_Encoder [NLP/자연어처리] Seq2Seq(3) - 트랜스포머(Transformer)_Encoder 2021.05.24 - [Study/NLP] - [NLP/자연어처리] Seq.. everywhere-data.tistory.com 2021.06.01 - [Study/NLP] - [NLP/자연어처리] pre-t..

[NLP/자연어처리] pre-trained model(2) - GPT-1(Generative Pre-Training of aLanguage Model)/OpenAI
2021.05.31 - [Study/NLP] - [NLP/자연어처리] ELMo(Embeddings from Language Models) [NLP/자연어처리] ELMo(Embeddings from Language Models) 2021.05.26 - [Study/NLP] - [NLP/자연어처리] Seq2Seq(3) - 트랜스포머(Transformer)_Encoder [NLP/자연어처리] Seq2Seq(3) - 트랜스포머(Transformer)_Encoder 2021.05.24 - [Study/NLP] - [NLP/자연어처리] Seq.. everywhere-data.tistory.com ELMo에 이어서 Pretrained 모델 중 하나인 GPT-1 에 대해서 이야기해보려 한다. 이는 OpenAI라고 하기..

[NLP/자연어처리] pre-trained model(1) - ELMo(Embeddings from Language Models)
2021.05.26 - [Study/NLP] - [NLP/자연어처리] Seq2Seq(3) - 트랜스포머(Transformer)_Encoder [NLP/자연어처리] Seq2Seq(3) - 트랜스포머(Transformer)_Encoder 2021.05.24 - [Study/NLP] - [NLP/자연어처리] Seq2Seq(1) - RNN을 이용한 시퀀스 투 시퀀스 [NLP/자연어처리] Seq2Seq(1) - RNN을 이용한 시퀀스 투 시퀀스 이전 RNN, LSTM, GRU에 대한 글을 보려면 아래 참조 20.. everywhere-data.tistory.com 2021.05.26 - [Study/NLP] - [NLP/자연어처리] Seq2Seq4 - 트랜스포머(Transformer)_Decoder [NLP/자연..

[NLP/자연어처리] Seq2Seq4 - 트랜스포머(Transformer)_Decoder
트랜스포머 인코더 부분은 아래 참고 2021.05.26 - [Study/NLP] - [NLP/자연어처리] Seq2Seq(3) - 트랜스포머(Transformer)_Encoder [NLP/자연어처리] Seq2Seq(3) - 트랜스포머(Transformer)_Encoder 2021.05.24 - [Study/NLP] - [NLP/자연어처리] Seq2Seq(1) - RNN을 이용한 시퀀스 투 시퀀스 [NLP/자연어처리] Seq2Seq(1) - RNN을 이용한 시퀀스 투 시퀀스 이전 RNN, LSTM, GRU에 대한 글을 보려면 아래 참조 20.. everywhere-data.tistory.com 해당 글은 딥러닝을 이용한 자연어 처리 입문의 내용과 Jay Alammar의 시각화 자료를 함께 정리한 내용입니다...