![[NLP/자연어처리] 순환신경망 (Recurrent Neural Network, RNN)](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2Fv4iQR%2Fbtq5j7GZqsT%2FGK8RYqjHi0tsnGVMSkbthk%2Fimg.png)
해당 포스팅은 김기현의 자연어처리 딥러닝 캠프의 내용과 파이토치로 시작하는 딥러닝 입문 의 내용을 정리한 것입니다.
우리는 시공간의 차원에 살고 있다. 그렇기 때문에 시공간에 정의된 수많은 문제를 해결하는 과정에서 시간의 개념을 넣어야하는 문제들도 많이 발생하고 있다. 텍스트 뿐 아니라 주식시장의 주가 예측이나 일기예보 등 많은 시간 관련 정보에 대한 문제들이 나오고 있다.
그 중 하나인 텍스트 분야의 경우, 단어들이 모여 문장이 되고, 문장이 모여 문서가 된다. 문장의 단어들은 앞뒤 위치에 따라 서로 영향을 주고받기 때문에 문서 내 문장들도 순서없이 입력을 넣으면 출력이 나오는 함수의 형태가 아니라 순차적으로 입력하면 그에 따라 hidden layer와 출력 결과가 순차적으로 반환되는 함수가 필요하다.
시간 또는 순서 정보를 사용하여 순차적인 결과를 반영하는 모델을 시퀀스(Sequence)모델이라고 한다. 입력과 출력을 시퀀스 단위로 처리하는 모델을 말한다. 우리는 먼저, 가장 기본적인 시퀀스 모델인 순환신경망(Recurrent Neural Network, RNN)에 대해서 이야기해 보고자 한다.
1. 순환신경망(Recurrent Neural Network, RNN)
가장 먼저 RNN과 비교하는 모델이 피드포워드 신경망인데, 앞서 배운 모델들은 전부 은닉층에서 활성화 함수를 지나 출력층 방향으로 가는 신경망을 말한다. RNN은 은닉층의 노드에서 활성화 함수를 통해 나온 결과값을 출력층 방향으로도 보내면서, 다시 은닉층 노드의 다음 계산의 입력으로 보내기도 한다. 이를 표현한 간단한 그림이 아래와 같다.
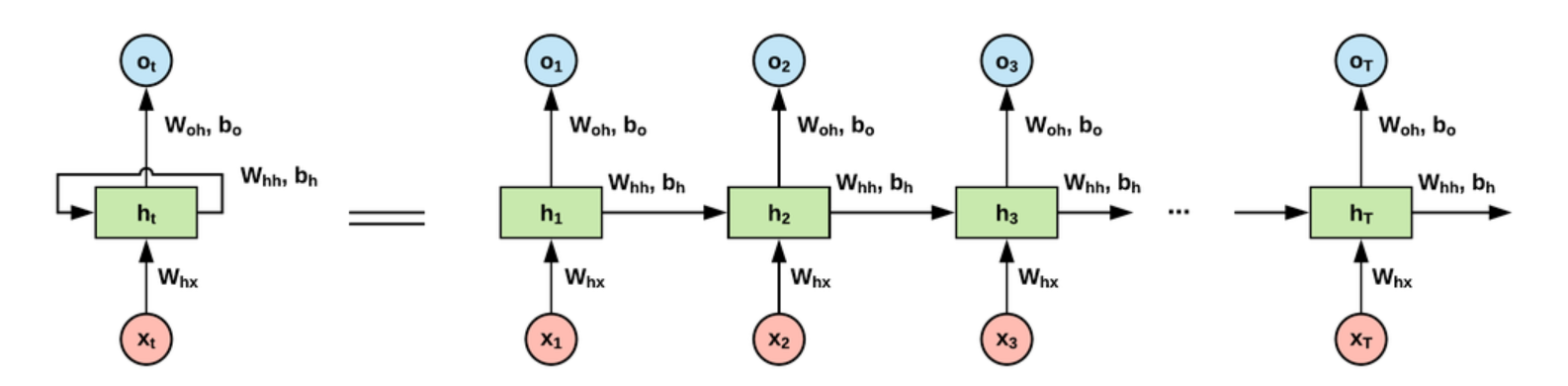
t시점의 입력 $ x_t $를 받아 t시점의 은닉층 $h_t$를 거쳐 t시점의 출력 $output_t$으로 출력됨과 동시에 t+1시점의 은닉층 $h_{t+1}$으로 입력된다. RNN에서 은닉층에서 활성화함수를 통해 결과를 내보내는 역할을 하는 노드를 셀(cell)이라고 하는데, 이 셀은 이전의 값을 기억하려고 하는 일종의 메모리 역할을 수행해 이를 메모리 셀 또는 RNN 셀이라고 한다.
메모리 셀이 출력층 방향으로 또는 다음 시점 t+1의 자신에게 보내는 갑을 은닉 상태(hidden state)라고 한다. 다시 말해 t 시점의 메모리 셀은 t-1 시점의 메모리 셀이 보낸 은닉 상태값을 t시점의 은닉 상태 계산을 위한 입력값으로 사용한다.
2. RNN의 종류
RNN은 입력과 출력의 길이를 다르게 설정할 수 있기 때문에 다양한 용도로 사용할 수 있다. 그래서 여러 종류의 RNN가 있는데, 다음과 같다.

- one to many(일 대 다) : 하나의 입력값으로 여러개의 출력값을 나타냄. 이미지를 단어들로 표현하는 문제 등에 사용.
- many to one(다 대 일) : 여러개의 입력으로 하나의 출력값을 나타냄. 텍스트 분류 문제, 감성분류 등에 사용
- many to many( 다 대 다) : 여러개의 입력값으로 여러개의 출력값을 나타냄. 챗봇, 번역 문제 등에 사용됨
3. RNN 셀의 구조(수식)
RNN 셀의 구조를 자세히 보면 아래와 같다.

현재 시점 t 에서의 은닉 상태 값을 $h_t$라고 정의하면, 은닉층의 RNN 셀은 $h_t$ 셀을 계산하기 위해서 총 두개의 가중치를 갖게 된다. 하나는 입력 층에서 입력 값을 위한 가중치 $W_t$이고, 하나는 이전 시점 t-1의 은닉 상태 값인 $h_{t-1}$을 위한 가중치 $W_h$이다. 이를 수식으로 표현하면 다음과 같다.
- $h_t = tanh(W_xx_t + W_hh_t-1 + b)$
- $y_t = \sigma(Wyh_t + b)$, 여기서 $\sigma$는 활성화 함수를 말한다.
두개의 가중치 행렬을 곱해 tanh 로 비선형 함수를 씌운 값이 $h_t$, 그것에 활성화 함수를 씌운 값이 출력값으로 나온다. 이 RNN 은닉층 연산을 그림으로 표현하면 아래와 같다.

이때 활성화함수로 주로 tanh가 사용되지만, ReLU로 바꿔 사용하는 시도도 있다고 한다. 위 식에서 각각의 가중치 $W_x, W_h, W_y$의 값은 모든 시점에서 값을 동일하게 공유한다. 만약 Deep RNN으로 은닉층이 두개라면 그 두개의 가중치는 서로 다르다.
출력층의 결과값인 $y_t$를 계산하기 위한 활성화 함수는 목적이 무엇이냐에 따라 다른데, 이진분류면 시그모이드, 다중분류면 소프트맥스 함수를 사용한다.
4. RNN의 역전파(BPTT)
RNN으로 피드포워드 된 이후에 역전파는 어떻게 될까? 각 time-step의 RNN에 사용된 파라미터 $\theta$는 모든 시간에 공유되어 사용된다. 따라서 앞서 구한 손실 $ \mathcal{L}$ 에 미분을 통해 역전파를 수행하면, 각 time-step별로 뒤로부터의 기울기 $\theta$가 구해지고 이전 time-stemp의 기울기가 더해진다. 즉 t가 0에 가까워질수록 RNN파라미터 $\theta$의 기울기는 각 time-stemp별 기울기가 더해져 점점 커진다. loss function 에 대한 수식은 다음과 같다.
$$\frac{\partial \mathcal{L}}{\partial \theta} = \sum_{t}\frac{\partial\mathcal{L}(y_t,\hat{y_t}}{\partial \theta}$$
즉 각 시점의 output에 나오는 값의 오차들을 평균한 것으로 역전파를 이루는 것이다.

5. 실습
이제부터는 nn.RNN()을 이용해서 실습해보도록 하자. 해당 문제는 다음 글자를 예측하는 문제로 짜보았다.
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optimsentence = "if you want me"
# make dictionary
char_set = list(set(sentence))
char_dic = {c:i for i, c in enumerate(char_set)}
print(char_dic)
>>> {'a': 0, 'w': 1, 'm': 2, 'f': 3, 't': 4, 'y': 5, 'n': 6, 'o': 7, 'i': 8, 'e': 9, 'u': 10, ' ': 11}여기서 if you want me의 문장으로 예측한다.
## predict next word
class TextRNN(nn.Module):
def __init__(self, input_size, hidden_size, n_layers):
super(TextRNN, self).__init__()
self.rnn = nn.RNN(input_size, hidden_size, n_layers, batch_first = True)
def forward(self, X, hidden):
outputs, _status = self.rnn(X, hidden)
return outputs, _status여기서 이제 nn.RNN 함수를 어떻게 활용할지 자세히 알아보도록 하자.

파이토치 도큐먼트를 보면 자세한 내용을 알 수 있다. 그러나 우리가 중점적으로 사용할 parameter는 input_size, hidden_size, num_layers다.
- input_size : 입력될 때 들어갈 수 있는 요소의 개수(vocabulary size)
- hidden_size : hidden_state를 거쳐서 나올 수 있는 요소의 개수(n_class)
- n_layers : hidden_satte를 몇개나 쌓을 것인지(Deep RNN에서 사용)
input_size = len(char_dic) # input 시 들어가는 character 수(vocab size)
hidden_size = len(char_dic) # output 시 나오는 character 수(number of class. 지금은 다음 단어 예측하는 거니까 vocab size 와 동일))sentence_idx = [char_dic[c] for c in sentence]
x_data = [sentence_idx[:-1]] # 마지막 글자 빼고 전부 input
x_data = [np.eye(len(char_dic))[x] for x in x_data] # one hot encoding
y_data = [sentence_idx[1:]] # 첫번째부터 마지막 까지 output
# transform as torch tensor
X = torch.FloatTensor(x_data)
y = torch.LongTensor(y_data)해당 문제 같은 경우, 입력이 "if you want m"까지 들어갔을 때 "f you want me"가 출력되는 문제다.
# declare RNN
rnn = TextRNN(input_size, hidden_size, 1)
# loss& optimizer setting
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(rnn.parameters(), lr = 0.001)어떤 문자가 나올지 예측하는 문제므로 loss function으로 CrossEntropy를 사용한다.
epochs = 1000
for epoch in range(epochs):
optimizer.zero_grad()
hidden = torch.zeros(1, 1, input_size)
outputs, _status = rnn(X, hidden)
loss = criterion(outputs.view(-1, input_size), y.view(-1))
loss.backward()
optimizer.step()
pred = outputs.data.numpy().argmax(axis = 2)
pred_str = ''.join([char_set[c] for c in np.squeeze(pred)])
if (epoch+1) % 100 == 0:
print('Epoch {}/{}, loss : {:.4f}, pred str : {}'.format(epoch, epochs, loss, pred_str))Epoch 100/1000, loss : 2.0285, pred str : f y u yant
Epoch 200/1000, loss : 1.6431, pred str : f ytu want e
Epoch 300/1000, loss : 1.4572, pred str : f ytu want e
Epoch 400/1000, loss : 1.3443, pred str : f ytu want me
Epoch 500/1000, loss : 1.2674, pred str : f you want me
Epoch 600/1000, loss : 1.2096, pred str : f you want me
Epoch 700/1000, loss : 1.1630, pred str : f you want me
Epoch 800/1000, loss : 1.1262, pred str : f you want me
Epoch 900/1000, loss : 1.0974, pred str : f you want me
Epoch 1000/1000, loss : 1.0741, pred str : f you want me
input과 hideen으로 들어갈 데이터의 형태는 아래와 같다.
- input : ( batch_size, timestemps, input_size)
- hidden : (n_layers, batch_size, hidden_size)
outputs, _status = rnn(X, hidden)또한 위와 같이 rnn함수를 통과하면, output 값과, hidden 값이 나오게 되는데 output은 hidden_state를 거쳐 나오는 모든 output을 말하며, _state는 마지막 hidden_state를 통해서 나온 결과값만을 말한다. 그래서 outputs[:,-1]과 _status는 같은 값을 가지고 있다.
만일 감성분석과 같은 분류모델을 만들기 위해서는 클래스를 아래와 같이 바꾸기만 하면 된다.
## predict classification
class TextRNN(nn.Module):
def __init__(self, input_size, hidden_size, n_layers):
super(TextRNN, self).__init__()
self.rnn = nn.RNN(input_size, hidden_size, n_layers, batch_first = True)
self.fc = nn.Linear(hidden_size, n_class, bias = True)
def forward(self, X, hidden):
outputs, _status = self.rnn(X, hidden)
output = self.fc(_status)
return output위와 같이 하면 마지막 hidden state의 결과를 가지고 linear함수를 거쳐 class의 개수에 따라 분류한다는 뜻이다.
6. 결론
RNN에 대해서 알아보았다. RNN의 형태가 가장 기본적인 순환 신경망의 형태이다. 추가로 여러 층이 쌓인 RNN의 형태로 Deep RNN도 있고, 기존의 정방향에 역방향이 추가되어 마지막 time step에서부터 거꾸로 역방향으로 입력받아 진행하는 양방향 RNN도 있다. 이에 대한 실습은 nn.RNN에서 parameter만 조절하면 바로 구현이 가능하다.
RNN의 한계도 분명히 존재한다. 이는 출력 결과가 바로 이전의 계산 결과에 의존도가 커 짧은 sequence에 대해서만 높은 효과를 보이고, 시점이(time steps)이 길어질수록 과거의 정보가 충분히 전달되지 못할 수 있다. 이를 보완하고 개선한 것이 LSTM, GRU가 있는데, 그것은 다음 포스팅에서 다뤄보도록 하자.
'Study > NLP' 카테고리의 다른 글
| [NLP/자연어처리] Seq2Seq(1) - RNN을 이용한 시퀀스 투 시퀀스 (0) | 2021.05.24 |
|---|---|
| [NLP/자연어처리] LSTM(Long Short-Term Memory), GRU(Gated Recurrent Unit) (0) | 2021.05.21 |
| [NLP/자연어처리] 단어의 표현(2) - 카운트 기반의 단어 표현 (0) | 2021.05.18 |
| [NLP/자연어처리] 단어의 표현(1) - 원핫인코딩과 워드투벡터(Word2Vec) (0) | 2021.05.14 |
| [NLP/자연어처리] 자연어처리 전처리(4) - 토치텍스트(TorchText) (0) | 2021.05.13 |