![[Python] Data Frame apply 함수 병렬처리 하는 방법](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FcV7Gyt%2Fbtq2CIqz7xp%2FFetXBzkMGY2w6DPGEvL2t1%2Fimg.png)
파이썬에서 apply함수를 사용할 때 데이터의 용량이 크거나, 힘수가 복잡할 경우 수행시간이 매우 느리다는 단점이 있다.
그렇다면 여러개의 프로세스를 사용해서 처리하는 방법을 고려해야 한다.
multiprocessing.cpu_count()를 통해 cpu 코어의 수를 가져와 함수를 생성 후 병렬처리를 할 수 있다.
groupby를 사용하지 않고 단순 apply를 사용한다면 아래와 같은 함수를 만든 후 사용하면 된다.
from multiprocessing import Pool
import multiprocessing
print('cpu counts:%d' % multiprocessing.cpu_count()) # cpu 최대 가용 수 확인
def parallelize_dataframe(df, func, n_cores = 8):
df_split = np.array_split(n_cores) # core의 개수만큼 df를 나눔
pool = Pool(n_cores) # pool을 core개수만큼 생성
df = pd.concat(pool.map(func, df_split)) # 나누어진 df를 func을 적용해서 수행 및 concat
pool.close()
pool.join() # 모두 완료될 때까지 대기
return df
참고링크와 같은 함수를 만들어 apply를 비교하게 되면 아래와 같다.
import random
import pandas as pd
import numpy as np
from multiprocessing import Pool
def add_features(df):
df['question_text'] = df['question_text'].apply(lambda x:str(x))
df["lower_question_text"] = df["question_text"].apply(lambda x: x.lower())
df['total_length'] = df['question_text'].apply(len)
df['capitals'] = df['question_text'].apply(lambda comment: sum(1 for c in comment if c.isupper()))
df['caps_vs_length'] = df.apply(lambda row: float(row['capitals'])/float(row['total_length']),
axis=1)
df['num_words'] = df.question_text.str.count('\S+')
df['num_unique_words'] = df['question_text'].apply(lambda comment: len(set(w for w in comment.split())))
df['words_vs_unique'] = df['num_unique_words'] / df['num_words']
df['num_exclamation_marks'] = df['question_text'].apply(lambda comment: comment.count('!'))
df['num_question_marks'] = df['question_text'].apply(lambda comment: comment.count('?'))
df['num_punctuation'] = df['question_text'].apply(lambda comment: sum(comment.count(w) for w in '.,;:'))
df['num_symbols'] = df['question_text'].apply(lambda comment: sum(comment.count(w) for w in '*&$%'))
df['num_smilies'] = df['question_text'].apply(lambda comment: sum(comment.count(w) for w in (':-)', ':)', ';-)', ';)')))
df['num_sad'] = df['question_text'].apply(lambda comment: sum(comment.count(w) for w in (':-<', ':()', ';-()', ';(')))
df["mean_word_len"] = df["question_text"].apply(lambda x: np.mean([len(w) for w in str(x).split()]))
return dftrain = parallelize_dataframe(train_df, add_features)
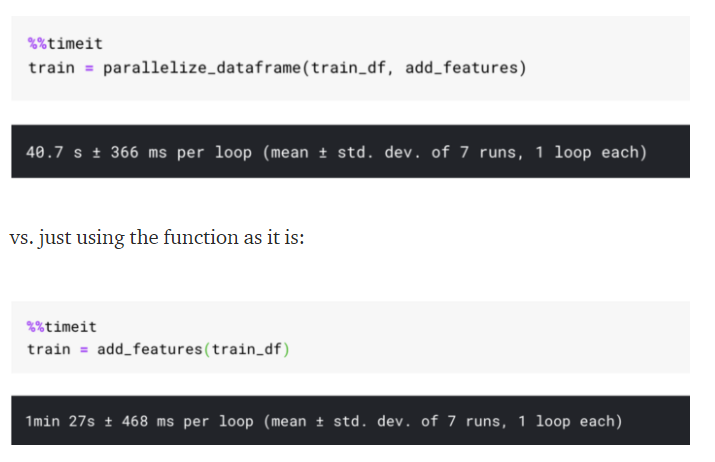
그런데 해당 함수는 groupby를 적용한 apply는 적용이 되지 않는다.
groupby 후 병렬처리하여 apply를 적용할 때에는 다음과 같이 작성하면 된다.
import pandas as pd
from joblib import Parallel, delayed
import multiprocessing
def temp_func(func, name, group):
return func(group), name
def applyParallel(dfGrouped, func, n_jobs = 16):
retLst, top_index = zip(*Parallel(n_jobs=n_jobs)(delayed(temp_func)(func, name, group)
for name, group in dfGrouped))
df = pd.concat(retLst, keys=top_index, axis = 1)
return df.reset_index()applyParallel(df.groupby(<key>), <function>)
실제로 필자가 함수를 적용한 결과 6시간이 소요되던 함수가 38분만에 종료된 것을 확인했다.
참고링크 :
towardsdatascience.com/make-your-own-super-pandas-using-multiproc-1c04f41944a1
Make your Pandas apply functions faster using Parallel Processing
Super Panda Man
towardsdatascience.com
stackoverflow.com/questions/26187759/parallelize-apply-after-pandas-groupby
Parallelize apply after pandas groupby
I have used rosetta.parallel.pandas_easy to parallelize apply after groupby, for example: from rosetta.parallel.pandas_easy import groupby_to_series_to_frame df = pd.DataFrame({'a': [6, 2, 2], 'b'...
stackoverflow.com