![[NLP/자연어처리] pre-trained model(3) - BERT(Bidirectional Encoder Representations from transformer)](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FbDjO0E%2Fbtq6jiHD0tG%2FwJ0F0Zuh2M0D2Pc1k9YeD1%2Fimg.png)
2021.05.31 - [Study/NLP] - [NLP/자연어처리] pre-trained model(1) - ELMo(Embeddings from Language Models)
[NLP/자연어처리] ELMo(Embeddings from Language Models)
2021.05.26 - [Study/NLP] - [NLP/자연어처리] Seq2Seq(3) - 트랜스포머(Transformer)_Encoder [NLP/자연어처리] Seq2Seq(3) - 트랜스포머(Transformer)_Encoder 2021.05.24 - [Study/NLP] - [NLP/자연어처리] Seq..
everywhere-data.tistory.com
[NLP/자연어처리] pre-trained model(2) - GPT-1(Generative Pre-Training of aLanguage Model)/OpenAI
2021.05.31 - [Study/NLP] - [NLP/자연어처리] ELMo(Embeddings from Language Models) [NLP/자연어처리] ELMo(Embeddings from Language Models) 2021.05.26 - [Study/NLP] - [NLP/자연어처리] Seq2Seq(3) - 트랜..
everywhere-data.tistory.com
이전 포스팅에서 ELMo, GPT에 대한 내용에 대해 기록을 남겨두었다. 갈수록 자연어 처리에 대한 공부가 재미있어지고 있는 요즘이다. 그런데, 이를 위한 실습도 좀 필요할 듯 하긴 하다. 이후 각종 예제들을 가지고 실습을 통해 깃허브에 업로드 해볼 예정이다. 우선 이론을 잘 알아두도록 하자.
오늘은 아직까지도 많이 각광받고 있는 BERT 알고리즘에 대해서 공부할 예정이다. 제작년 2019년 말, BERT에 대한 관심은 뜨거웠었다(그게 벌써 제작년이라는게 소름끼치지만...) 내가 다니고 있는 회사에서도 BERT관련 강의와 스터디를 많이 했고, 그에 따른 연구 또한 많이 이루어지고 있는 듯 하다. 나도 BERT에 대한 이해가 당시엔 부족해 하기 어려웠는데, 이제는 차차 따라가고 있는 중이다. 이제부터 공부를 시작해보자.
1. BERT(Bidirectional Encoder Representations from transformer)

GPT-1, 즉 OpenAI 트랜스포머 모델은 fine-tune 할 수 있는 pre-train된 모델은 제시한다. 그러나 LSTM에서 Transformer로 넘어가기에 한계가 있는 부분이 있었다. LSTM은 양방향으로 학습할 수 있어 bi-directional model이었는데, GPT-1는 forward language model이기 떄문에 한방향으로만 학습할 수 밖에 없다는 것이다. 양방향의 맥락을 모두 확인할 수 없을까에 대한 고민에서 시작되고, 고안된 방법론이 바로 BERT였다. (Jay Alammar 블로그에서 설명을 재밌게 한다. “Hold my beer”, said R-rated BERT.")
BERT는 Bidirectional Encoder Representations from transformer의 약자로 transformer에서 encoder만을 사용하여 bi-direction하게 사용하는 모델을 이야기 한다. BERT는 두가지 목적을 가지고 있는데,
- 첫째, Masked_language model(MLM) : 양방향성(bi-directional) pre-training 으로 언어를 표현하는 것
- 둘째, 다음 문장이 corpus에서의 실질적인 다음 문장인지 예측하는 것(Next sentence prediction, NSP)
이 두가지 이다. 아래 그림을 보면, Pre-training 후에 BERT위에 하나의 레이어만 추가함으로써 여러가지 task를 처리할 수 있음을 알 수 있다.

2. BERT 아키텍처
BERT의 이름처럼 BERT는 Transformer의 Encoder만 사용하는 것을 알 수 있다.


논문에서 말하는 BERT는 크게 두개의 아키텍쳐가 있는데, BERT base는 layer의 수를 12개, hidden embedding size를 768차원, attention head의 수를 12개로 주었고(이전의 OpenAI GPT와 비슷한 크기의 모델), BERT large는 layer의 수를 24개, hidden embedding size를 1024개, attention head의 수를 16개로 주었다. 정리하면 아래와 같다.
- BERT base
- layer 개수 : 12개
- hidden embedding size : 768차원
- attention head의 개수 : 12개
- 파라미터 개수 : 110M
- BERT large
- layer 개수 : 16개
- hidden embedding size : 1024차원
- attention head의 개수 : 16개
- 파라미터 개수 : 340M
3. BERT의 pretraining 구동과정
BERT를 이용해 여러가지 down stream task를 해결하려면, single sentence 또는 한 쌍의 sentences가 필요하다. 그런데 여기서 정의하는 sentence는 우리가 알고있는 주어 + 동사 하나로 이루어진 문장이 아니다. 논문에서 정의한 sentence는 여러개의 단어들이 모인 하나의 단어 집합을 말한다. 또한 sequence는 그러한 sentence가 하나 또는 두개(Q&A 등)가 있는 것을 말한다.

BERT에서 bi-directional language모델을 사용할 수 있는 이유는, input 으로 sentence를 입력할 때, 일정한 비율(논문에서는 15%)로 masking처리를 해서 해당 단어를 볼수 없도록 하기 때문이다. language modeling은 알 수 없는 다음의 단어를 예측하는 테스크라면, 트랜스포머의 encoder는 self-attention층에서 모든 단어들을 봐야 했기 때문에 사용하기 어려운 문제가 있었는데, 그 문제를 masking으로 해결한 것이다. 단순히 입력의 15%를 마스킹 한 것 분만이 아니라, BERT는 나중에 fine-tune과정을 위해 masking 비율의 일부를 랜덤하게 다른 단어로 바꿔치기 해서 모델에게 원래의 맞는 단어를 예측하게 하기도 한다.
여기서 [CLS]는 모든 sequence의 첫 토큰이라는 의미로 사용되고, [SEP]은 두개의 sentence를 구분하기 위한 토근이라는 의미로 사용된다.

위 그림에서 C의 의미는 최종 학습의 결과에 대한 hidden vector를 의미하는데 이 위해 simple linear를 얹어서 분류모델에 사용한다. 또한 T_N은 N번째 위치에 있는 hidden layer에 대한 결과를 의미하는데, 추후 언급하겠지만 NER같은 태깅의 문제에서 사용된다.
3.1 Input Representation

BERT에 sentence를 입력할때는 세개의 Embedding값을 더해서 입력하게 되는데,
- Token Embedding : 30,000개의 token vocabulary에서 각 단어에 대한 word embedding 값.
- Segmentation Embedding : sentence가 두개 일때 각 단어가 어느 sentence에 속하는지 구별하는 값.
- Position Embedding : 각 단어의 위치에 대한 embedding 값
위 세개의 Embedding 값들을 각 더해준 값이 최종 input representation이 된다.
3.2 Pre-training BERT
BERT를 pre-training하기 위해서는 입력하는 sequence 안의 token들 중 15%를 masking한 [MASK]라는 토큰으로 대체한다. 그 후 위에서 구한 Embedding값을 더한 후 BERT모델을 통해 self-attention을 거친 후 FFNN + Layer Norm을 거친 후 각 token에 대한 단어를 softmax로 구하도록 학습하는 것이다. 즉 mask된 단어를 BERT를 거친 후에는 원래 정답이었던 단어로 예측하도록 학습하는 것이 BERT의 역할이다.

ELMo의 경우에는 bidirectional한 모델을 forward와 backward 모델을 각각 따로 학습시켰다면, BERT의 경우는 self-attention을 통해 한번에 학습했다고 볼 수 있다.
여기서는 문제가 하나 발생할 수 있는데, pretraining 과정에서는 token에 대한 마스킹을 수행할 수 있지만, fine-tunning에서는 마스킹을 수행하지 않기 때문에 mismatch되는 상황이 발생할 수 있다. 그를 해결하기 위해서 mask하기로 한 token이 15퍼센트 정해졌다면, 학습을 할 때 학습하는 횟수 중 80%는 mask token으로 바꾸고, 10%는 전혀 다른 뜬금없는 단어로 변경하고, 나머지 10%는 원래 단어 그대로 학습한다.
3.3 Next Sentence Prediction(NSP)
QA 문제나 Natural Language Inference와 같은 문제에 대해서는 두 문장간의 관계에 대한 학습이 필요하게 된다. ELMo와 GPT같은 경우는 문장단위로 학습을 했기 때문에 두 문장간의 관계를 알기 어려웠지만, BERT는 두개의 문장을 [SEP]토큰을 줌으로써 두개의 문장을 함께 학습한다. 이로 고안된 방법이 A Binarized next sentence prediction task인데, 50%의 두 문장 간 관계가 있는 문장(연속된 문장), 50%의 두 문장 간 관계가 없는 문장(연속되지 않은 문장)을 입력해서 학습시킨다. 이 방법을 통해 QA 문제나 NLI 문제에서 큰 성능의 효과를 볼 수 있었다.
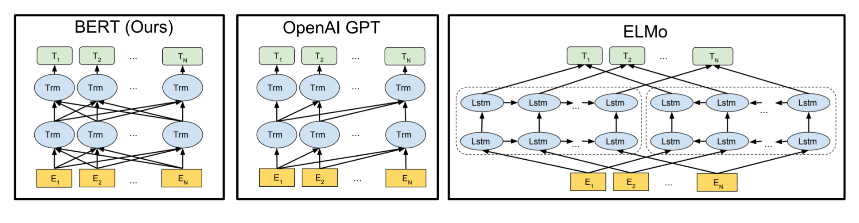
4. BERT와 OpenAI, ELMo의 차이
BERT와 OpenAI, ELMo. 세 모델간의 pre-training 구조의 차이를 시각적으로 표현한 그림이 있다.
5. BERT의 FineTuning
논문에서는 BERT의 마지막 hidden layer에 하나의 layer 만 태우면 어떤 task의 문제든 해결할 수 있다고 주장한다. 아래 그림은 각 task에 대한 bert의 fine tuning 시각화 방식이다.

- Sentence pair Classification Tasks : CLS의 마지막 hidden layer 위에 linear layer를 더해 Classification 학습
- Single sentence Classification Tasks : 단일 문장에 대한 Classification 또한 두개의 sentence와 같이 CLS의 마지막 hidden layer에만 라벨을 붙인 linear layer를 더해 classification을 학습한다.
- Question Answering Tasks(질의 응답) : 질의 응답에 대한 문제는 paragraph 안 어떤 단어가 응답하는데에 대한 중요한 key point가 되는지를 표시하는 Start/End label에 대한 classification layer를 더해준다.
- Single Sentence Tagging Tasks : 하나의 single sentence에 대해 각각의 토큰마다 객체인식과 같은 문제에서는 모든 token에 대해 layer를 더해 tagging 문제를 해결한다.
'Study > NLP' 카테고리의 다른 글
| [NLP/자연어처리] Transfer Learning(전이학습)에 대한 소개 (0) | 2021.10.17 |
|---|---|
| [NLP/자연어처리] Beyond BERT (1) | 2021.06.08 |
| [NLP/자연어처리] pre-trained model(2) - GPT-1(Generative Pre-Training of aLanguage Model)/OpenAI (0) | 2021.06.01 |
| [NLP/자연어처리] pre-trained model(1) - ELMo(Embeddings from Language Models) (0) | 2021.05.31 |
| [NLP/자연어처리] Seq2Seq4 - 트랜스포머(Transformer)_Decoder (0) | 2021.05.26 |