![[NLP/자연어처리] Beyond BERT](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FT9bl8%2Fbtq6JnifTCg%2FAwpIdzIUbgjwOM79cBYfd1%2Fimg.jpg)
[NLP/자연어처리] pre-trained model(3) - BERT(Bidirectional Encoder Representations from transformer)
2021.05.31 - [Study/NLP] - [NLP/자연어처리] pre-trained model(1) - ELMo(Embeddings from Language Models) [NLP/자연어처리] ELMo(Embeddings from Language Models) 2021.05.26 - [Study/NLP] - [NLP/자연어..
everywhere-data.tistory.com

BERT와 ELMo, GPT-3가 등장하면서 자연어처리 분야의 발전은 날로 늘어가고 있다. 이후로 LM 모델에 대한 연구가 BERT기반으로 한 연구들이 등장하고 있으며, 효과적으로 언어모델을 학습하기 위한 방법들이 제안되고 있습니다.
오늘은 고려대학교 산업경영공학과 민다빈 석사 연구생님이 발표한 자료를 기반으로 BERT기반으로 출시된 모델에 대해서 정리해보려고 합니다.

1. Remind Transformer& BERT
- Transformer
- Sequence to Sequence 기반의 translation 모델
- Encoder & Decoder 구조
- Long-term dependency problem, parallelization에 대한 문제를 Self-attention으로 해결
- Bi-directional contextualized representation
- Positional Encoding, Multi-head attention, output masking

- BERT
- Transformer Encoder 만을 사용해서 여러개 쌓음
- Pre-training & Fine-tunning
- input : 연속 또는 불연속한 2개의 segment(1개 이상의 연속된 문장)
- pre-training task : Masked language modeling(MLM), Next sentence prediction(NSP)
- fine-tunning : task별로 입출력이 변경됨
2. BERT를 기반으로 한 4가지 방법
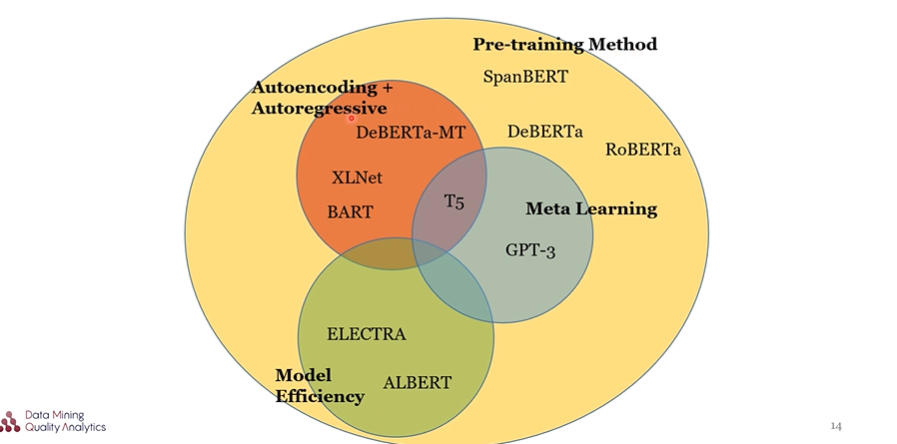
2.1 Pre-training method
사전훈련 방식 개선을 통해 성능을 향상시키는 모델로, SpanBERT, XLNet, RoBERTa, ALBERT, BART, ELECTRA, GPT-3, T5, DeBERTa 등이 이러한 방식을 사용했다.
2.2 Autoencoding(AE) + Autoregressive(AR)
MLM을 통해 학습되는 BERT는 MASK 토큰 간 dependency를 학습할 수 없어 차용한 방안으로 XLNet, BART, DeBERTa-MT 등이 이에 속한다.
2.3 Model efficiency
더 적은 파라미터와 더 적은 computation cost로 성능을 유지하는 방안을 고안해 낸 방식으로 ALBERT, ELECTRA가 있다.
2.4 Meta learning
fine-tunning을 하지 않고 모델을 일반화하는 방안으로 Generalized model, few-shot, zero-shot 이 있으며, GPT-3, T3모델이 이에 속한다.
3. Model 소개
3.1 XLNet
Auto Encoding 방식의 BERT의 한계점을 지적하며, AE + AR구조를 제안했다. Transformer의 Decoder를 쌓아올린 것과 같은 구조를 가지고 있고, 개요는 language model의 token을 마구 섞는 permutation을 사용하여 input으로 넣고 Autoregressive 모델을 사용한 것이다.
two stream self attention을 사용하여 두가지 이상의 정답을 내뱉어야 하는 부분에 대해서 해결했다고 한다.
3.2 SpanBERT (워싱턴, 프린스턴대, Allen AI Lab, Facebook)
- Span masking : BERT의 Pre-training 방석을 개선했는데, Span masking 을 사용하여 임의의 독립적인 단어를 masking하는 BERT의 방식 대신에 한 개 이상의 연속된 토큰이 masking되는 방식을 사용하였다. 모델은 masking된 모든 토큰들에 대해 각각 예측되어야 한다.
- Span boundary objective(SBO) : Span masking을 취한 상태에서 span의 단어를 예측할 때 Span boundary(가장자리)에 있는 token으로 span안의 토큰들을 예측하는 방식이다.
- Next Sentence Prediction을 삭제함으로 Single sentence training으로 Span masking 방식만 사용했다. 그렇기에 하나의 segmentation을 넣을 수 있게 되면서 보다 더 긴 segmentation을 입력할 수 있게 되었다.

3.3 RoBERTa(워싱턴대, FaceBook)
- BERT는 underfitting 되었다 : -> BERT를 최적화하는 방법 (Data 수를 늘리고 batch size를 키운다.)
- NSP 삭제, single sequence training
- dynamic masking : input이 들어갈 떄마다 masking을 새로 한다.
- BERT와 XLNET보다 좋은 성능을 냈다.
3.4 ALBERT(Google)
- BERT를 더 크게 만들기 위해서 모델을 효율화시킨다.
- BERT의 파라미터 수를 줄여도 더 깊은 모델을 만들어 성능을 유지시켰다.
- Factorized embedding parameterization : 차원의 크기가 큰 워드 벡터를 작은 차원의 Embedding크기로 줄이고, hidden layer의 사이즈만큼 다시 embedding 시키는 방법. parmeter를 줄일 수 있다는 장점

- Cross-layer parameter sharing : transformer encoder를 전부 같은 parmeter로 변환
- Sentence order prediction(SOP) : input을 구성할 때, 주제가 같은 segment로 연속된 두 segment와 순서를 바꾼 segment 를 이용해 문맥의 일관성에 대해 훈련할 수 있도록 함.
3.5 BART(Facebook)
- AE + AR 구조 제안
- 기존 transformer의 구조를 거의 그대로 사용
- activation function을 ReLU에서 GeLUs 로 변경
- Noise flexibility : noise있는 input을 이용해서 masking에 적용하는 방식 -> Text infilling 적용

- Classificaton의 fine-tunning : pretrain때 사용하지 않았던 randomly initilazed encoder 추가

- BART는 Text Generalization에서 우수한 성능을 보일 수 있었음.
3.6 ELECTRA(스탠포드대, Google)
- MLM 에 대한 지적 : 오직 masked token에 대해서만 학습이 이루어진다 -> 비효율적이다.
- GAN과 유사한 방식의 구조를 제안 : Sample efficient pe-training task
- Generator를 통해 복원된 단어가 정답인지 아닌지 token별로 예측을 수행
- GAN과 다른 점 : Generator가 discriminator를 이기려고 하는 것이 아니라 자신이 생성하는 문장의 likelihood를 최대화하는 것 뿐

3.7 T5 & GPT-3( google/openAI)
- fine-tunning 기반 모델의 한계를 지적
- downstream task를 풀기 위해 많은 레이블 데이터 필요
- fine-tuning시 특정 task 외의 문제에 대한 일반화 능력 상실
- Meta-learning : task의 종류 자체를 텍스트로 처리하여 모델 인풋에 함께 사용
- T5 : multitask learning, transformer encoder-decoder 구조, 110억개의 파라메터
- GPT-3 : few-shot learning, transformer decoder 구조 사용 1750 억개의 파라메터
3.8 DeBERTa(Microsoft)

- BERT, RoBERTa 계열의 발전(21년 2월 기준)
- Disentangled attention mechanism : 토큰 하나의 임베딩 값을 두개의 벡터로 나타냄(content, position), 네가지 경우에 대한 cross-attention을 거쳐 최종 값을 사용 => 두 단어의 관계가 단어의 의미 뿐 아니라 상대적 위치까지도 고려가 되어야 한다.
- Enhanced mask decoder : 토큰의 절대 위치에 대해서 어떻게 사용할 것인가. => 모든 transformer encoder를 거친 이후에 softmax직전에 positional encoding을 더해줌
- 기존 아이디어 채택
- NSP 삭제(RoBERTa)
- AE + AR for generation task(UniLM)
- pretraining : 한 배치 일부는 AE, 일부는 AR 마스킹 적용
- fine-tunning : AR 마스킹만 적용
- Span masking(SpanBERT)
참고영상
https://www.youtube.com/watch?v=L_NpC0qcDkM