![[NLP/자연어처리] 이전의 자연어처리 방법론 - Word Embedding 과 Skip-Gram](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FdFqdEm%2FbtrlJN0kCdM%2FASEKskqajtUuwkDIfpriH1%2Fimg.png)
오늘의 포스팅은 Bert와 같은 pretrained language model 이 나오기 전 자연어처리 문제를 어떻게 해결했는지에 대한 이야기를 포스팅해보려고 한다. 이전에 비슷한 내용의 포스팅을 한적이 있는데, 그 내용을 정리하는 차원으로 포스팅을 해보려고 한다.
2021.05.14 - [Study/NLP] - [NLP/자연어처리] 단어의 표현(1) - 원핫인코딩과 워드투벡터(Word2Vec)
[NLP/자연어처리] 단어의 표현(1) - 원핫인코딩과 워드투벡터(Word2Vec)
해당 내용은 김기현의 자연어 처리 딥러닝 캠프 파이토치편 및 Pytorch로 시작하는 딥러닝 입문읽으며 발췌 및 정리하였으며, 필요에 따라 추가로 검색하여 내용을 보충했습니다. 이전 글 참고
everywhere-data.tistory.com
1. 워드 임베딩(Word Embedding)
워드 임베딩이란, 수많은 단어들을 일정한 숫자열의 벡터값으로 압축하는 것을 말한다. 단어를 벡터화 시킨다고 해서 워드 투 벡터(Word2Vec) 이라고도 한다. 기존에는 단어들을 컴퓨터로 인식할 때에는 범주형 단어로, 그것은 원핫 인코딩으로 입력해야했지만 그렇게하면 단어사전의 단어 수가 늘어날수록 차원이 늘어나고, sparse한 데이터가 된다. 이를 위해 단어를 일정한 길이의 벡터값으로 축소하면서 주변(context window)에 같은 단어가 나타나는 단어일수록 비슷한 벡터값을 가져야 한다는 모티브를 가지고 워드임베딩 방법론을 개발하게 되었다.
이러한 방법론은 문장의 문맥에 따라 정해지는 것이 아닌, 주변의 단어에 따라 정해지게 되며, 주변 단어의 단어 개수를 몇개까지 허용하냐에 따라서 embedding의 성격이 바뀔 수 있다. 다시 말하면 주변 단어를 하나만 쓰느냐, 두개를 쓰느냐, 또는 앞의 단어만 볼 것이냐, 뒷 단어까지 볼 것이냐에 따라 축소된 벡터값의 셩격이 달라질 수 있다는 뜻이다.

2. CBOW와 Skip-gram
CBOW(Continuous Bag of Words)와 Skip-gram은 설명할 때에 항상 쌍처럼 같이 나오는 이론이다. CBOW는 주변에 있는 단어들을 가지고, 중간에 있는 단어들을 예측하는 방법을 말하며, 반대로 Skip-Gram은 중간에 있는 단어로 주변의 단어들을 예측하는 방법이다.
학습하기 전의 input 과 output을 단어의 원한 인코딩으로 입력한 후 학습할 때 사용된 차원의 가중치행렬이 임베딩 벡터가 되는 것이다. 자세한 학습 방법은 아래 이전 포스팅에서 확인할 수 있다.
2021.05.14 - [Study/NLP] - [NLP/자연어처리] 단어의 표현(1) - 원핫인코딩과 워드투벡터(Word2Vec)
[NLP/자연어처리] 단어의 표현(1) - 원핫인코딩과 워드투벡터(Word2Vec)
해당 내용은 김기현의 자연어 처리 딥러닝 캠프 파이토치편 및 Pytorch로 시작하는 딥러닝 입문읽으며 발췌 및 정리하였으며, 필요에 따라 추가로 검색하여 내용을 보충했습니다. 이전 글 참고
everywhere-data.tistory.com
이러한 전략들은 주변단어들을 예측하도록 하는 과정에서 적절한 단어의 임베딩을 할 수 있으며, 그것이 정보의 압축을 의미한다는 것이 주요 전략이다. 그러므로 단어 임베딩 뿐만이 아니라, 다양한 범주를 가지고 있는 항목을 임베딩하는 방법이 많이 사용되고있다. 그 중 대표적인 것이 item2vec, 물건들을 벡터화 시켜 정보를 압축하는 방법이다.
3. Embedding Layer
이와 같은 워드 임베딩을 하는 과정에서 원핫 인코딩된 이산 생블의 벡터를 받아서 학습하는 과정에 나오는 가중치 행렬은 연속벡터로 변환된다. Embedding layer의 가장 큰 장점은 높은 차원의 벡터를 효율적으로 계산할 수 있도록 낮은 차원의 연속 벡터로 변환된다는 점이며, loss를 최소화 하는 과정에서, 임베딩 레이어 중 자연스럽게 비슷한 쓰임새를 갖는 단어는 비슷한 벡터를 갖게 된다.
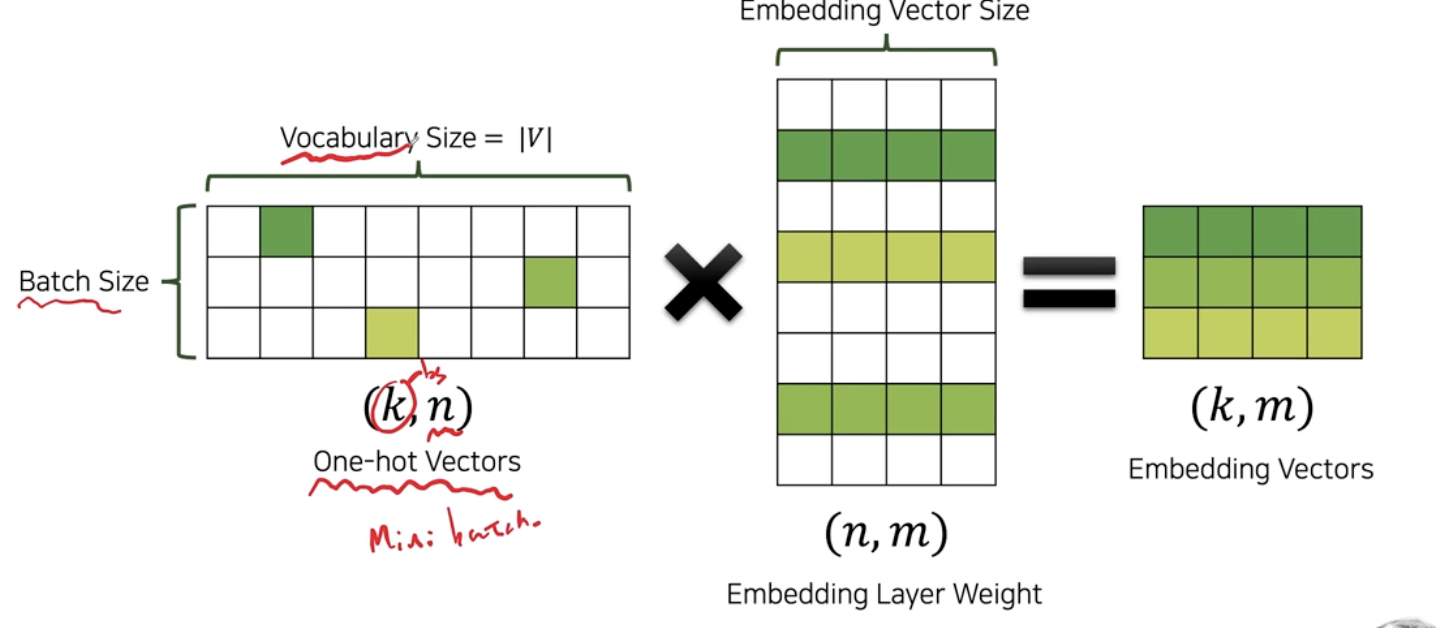
4. Word Embedding의 장점과 단점
장점은 위에서 많이 언급했듯, 높은 차원의 벡터를 효율적으로 계산할 수 있도록 정보의 압축이 일어났다는 점이다. 그래서 NLP이외의 영역에서도 응용의 발판이 일어나 Item2Vec과 같은 방법론들이 나오게 되었다. 그러나 치명적인 단점으로 NLP영역에서 실전에서는 잘 사용이 안되게 되는데, 그것은 문맥을 이해할 수 없다는 점이다. 동음이의어와같은 중의성을 가진 단어들에 대한 처리가 없기 때문에 "밤에 모기가 있다"의 "밤"과, "따끈따끈한 밤이 먹고싶다"의 "밤"을 다른 단어로 인식할 수 없다.
치명적인 단점이 있지만, 어쩌면 NLP의 조상과도 같은 이론이기 때문에 자연어처리를 공부하기 위해서는 반드시 짚고 넘어가야 하는 부분이기에 이렇게 포스팅했다. 다음 포스팅에서는 Transformer에 대해 남겨보려고 한다.
'Study > NLP' 카테고리의 다른 글
| [NLP/자연어처리] Self-supervised Learning (0) | 2021.10.24 |
|---|---|
| [NLP/자연어처리] Transfer Learning(전이학습)에 대한 소개 (0) | 2021.10.17 |
| [NLP/자연어처리] Beyond BERT (1) | 2021.06.08 |
| [NLP/자연어처리] pre-trained model(3) - BERT(Bidirectional Encoder Representations from transformer) (0) | 2021.06.01 |
| [NLP/자연어처리] pre-trained model(2) - GPT-1(Generative Pre-Training of aLanguage Model)/OpenAI (0) | 2021.06.01 |